Episode 3: Infrastructure as Code & Platform teams
Published: Sunday, Oct 19, 2025 • Duration: 92 minutes • Season 1
Download MP3 | Watch on YouTube
https://aws.amazon.com/cloudcontrolapi/
https://s.natalian.org/2025-10-19/CommunityDay_Malaysia_2025.pptx
summarize "https://youtu.be/gkoxHncYCTk" --timestamps --slides
This detailed conversation between two seasoned infrastructure engineers explores the evolving landscape of Infrastructure as Code (IaC), the technical limitations of Terraform, and the organizational challenges of building effective platform teams. The discussion centers on the transition from simple configuration files to complex programmatic abstractions and the introduction of “Terra Constructs,” a project designed to bring the developer experience of AWS CDK to the Terraform ecosystem.

The Evolution and Complexity of Terraform
Terraform was originally built on the concept of plugins and providers to manage cloud resources like VPCs and subnets. A decade ago, the number of “knobs and dials” for these resources was limited, making a simple configuration file sufficient. However, as the cloud evolved to include serverless components, SNS topics, and complex integration patterns, Terraform’s declarative nature began to struggle. To keep up, the language introduced programmatic features like for_each loops, list comprehensions, and local blocks. This has led to the creation of massive community modules that often feature over 45 variables and complex tertiary conditionals, making it difficult for engineers to understand how variables interact or trickle down into resource configurations. the cloud became way more complex… a lot more serverless is now being part of a lot of the tech stack Originally, Terraform aimed to be “dumb” to prevent users from shooting themselves in the foot, but the reality of modern cloud architecture has forced a level of complexity that a simple config file can no longer easily manage.
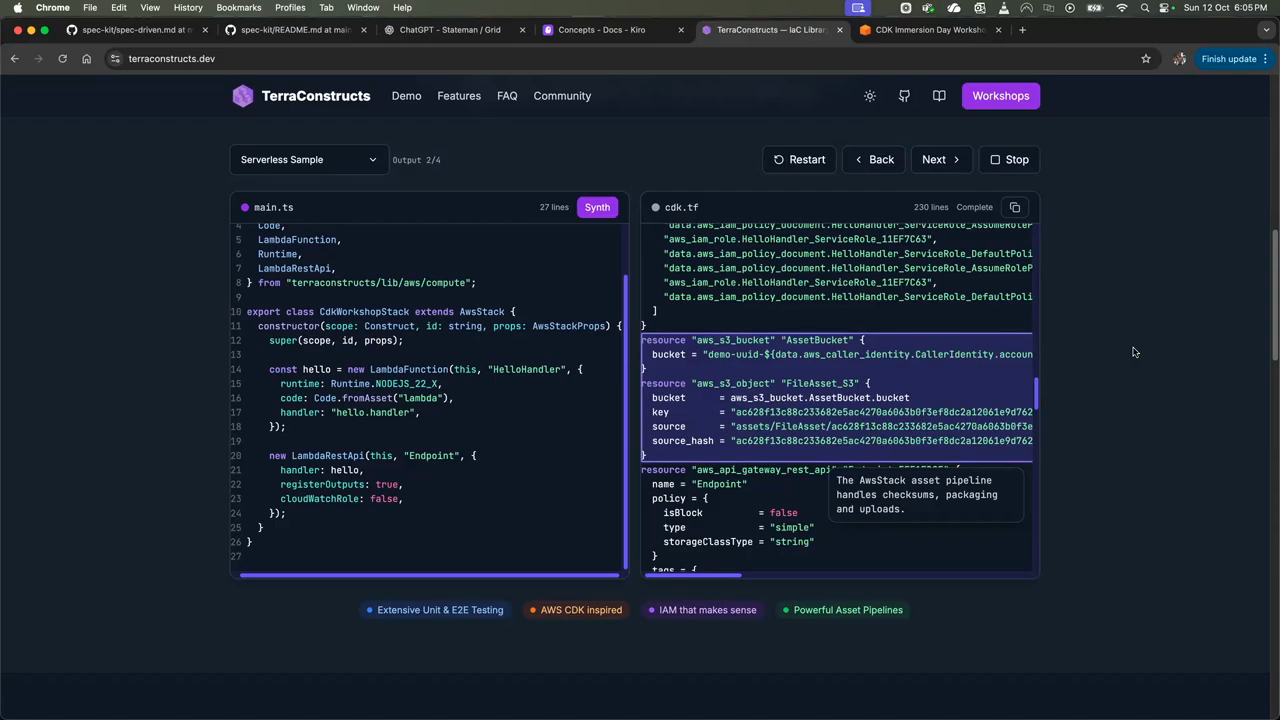
The Serverless Integration Challenge
Provisioning AWS Lambda functions in raw Terraform is often a “nightmarish” experience because the provider only covers the bare minimum resources required by the API. Engineers must manually configure Lambda permissions, IAM roles, and CloudWatch logging groups, then explicitly bind them together. This lack of high-level abstraction is particularly painful in serverless environments where business logic is spread across multiple components. AWS CDK solves this by providing “constructs” that understand service integration patterns. For example, a single line of CDK code can handle an entire asset pipeline—bundling code, uploading it to S3, and ensuring the Lambda can access it. Terra Constructs is an attempt to port these high-level developer experiences to Terraform, allowing engineers to use TypeScript to define complex patterns like Lambda chaining or EventBridge rules while still outputting standard Terraform resources. This approach recognizes that in the serverless world, infrastructure and business logic are too tightly coupled to be managed through decoupled, low-level configuration files.
Organizational Realities and Refactoring
Terraform remains the dominant tool for Infrastructure as Code due to its massive industry adoption and mindshare. In many organizations, platform teams use Terraform to bootstrap core infrastructure like VPCs and EKS clusters, while product teams may prefer the flexibility of CDK. This creates a need for “aligning things” and providing clear integration points between different execution engines. A central theme of the discussion is refactoring, which is described as a pivotal part of infrastructure management. As projects grow, resources often need to be moved from a single project into shared layers or owned by a dedicated platform team. Without the ability to refactor stacks easily, organizations end up with “stale” infrastructure or projects that are impossible to deprecate because of hidden dependencies. The speakers also touch on the AWS Project Development Kit (PDK) and tools like CDK DIA, which can generate high-level diagrams to help teams visualize the intent and meaning behind their infrastructure constructs, a feature that is notoriously difficult to achieve with standard Terraform modules.

Terra Constructs vs. Existing Adapters
The conversation dives into the technical differences between Terra Constructs and other tools like HashiCorp’s CDKTF or the AWS Adapter for CDK. While CDKTF provides the foundation for using TypeScript with Terraform, it lacks the high-level service integration patterns (Level 2 constructs) found in AWS CDK. The AWS Adapter for CDK attempts to map CloudFormation resources to Terraform using the AWS Cloud Control API, but this often results in a loss of functionality. The Cloud Control API is autogenerated and sometimes lacks the “curated” experience of the manually maintained AWS provider. For instance, the manual provider can hide the complexity of “JSON patches” required by certain API Gateway endpoints, providing a much cleaner interface for the user. Terra Constructs aims to bridge this gap by reimplementing core CDK features—like asset bundling and IAM principle management—directly on top of the popular, manually maintained Terraform AWS provider. This ensures that existing ecosystem tools for linting, security scanning, and cost calculation still work perfectly while providing a superior developer experience.
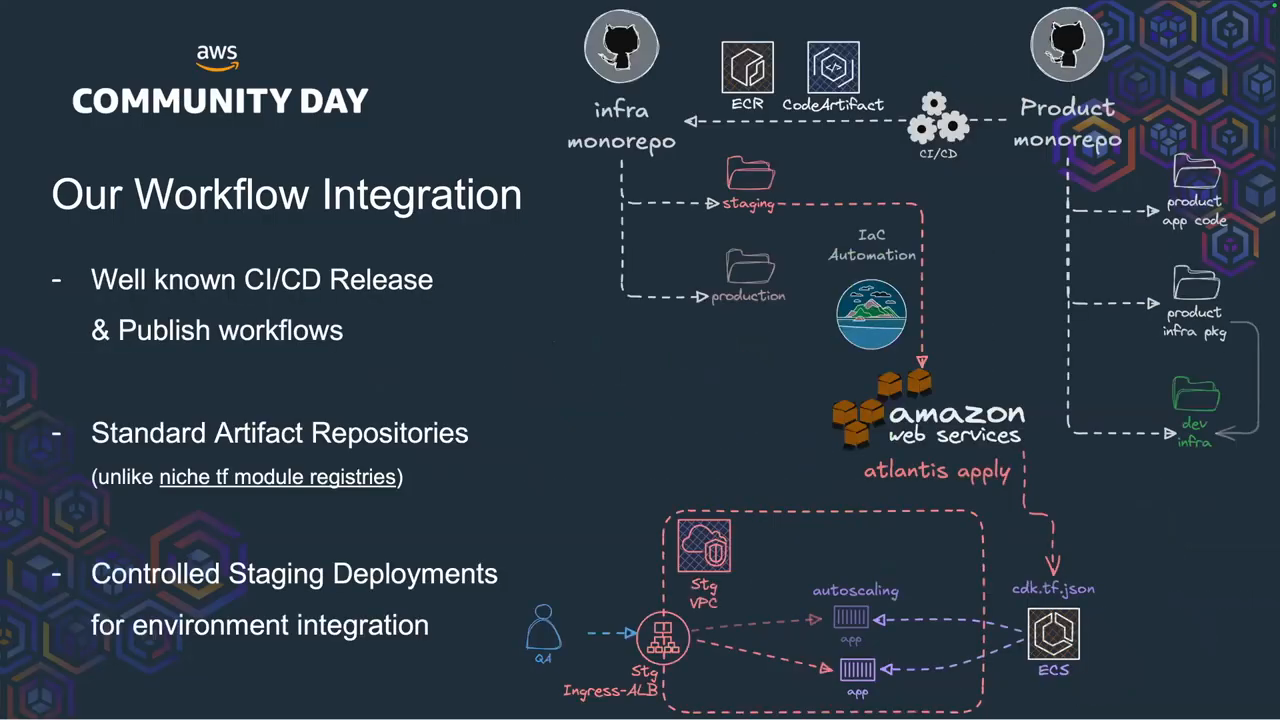
Integration Registries and State Management
A major point of contention in infrastructure engineering is how to handle dependencies between different teams and stacks. The engineers discuss the “Integration Registry” pattern, often implemented using AWS SSM Parameter Store, where one team publishes resource IDs for others to consume. While this sounds simple, it frequently leads to a “recipe for disaster” because it introduces a layer of indirection that can become stale. There is often no way to track which consumers are reading a specific key, making it dangerous to change or delete values. The speakers suggest that a better approach is using native Terraform outputs or even a centralized JSON file in a Git repository to coordinate secrets and account details. This provides a clear change log and avoids the “sprawl” associated with arbitrary SSM paths. The goal is to maintain direct connectivity between providers and consumers to ensure that infrastructure changes are predictable and visible across the entire organization.
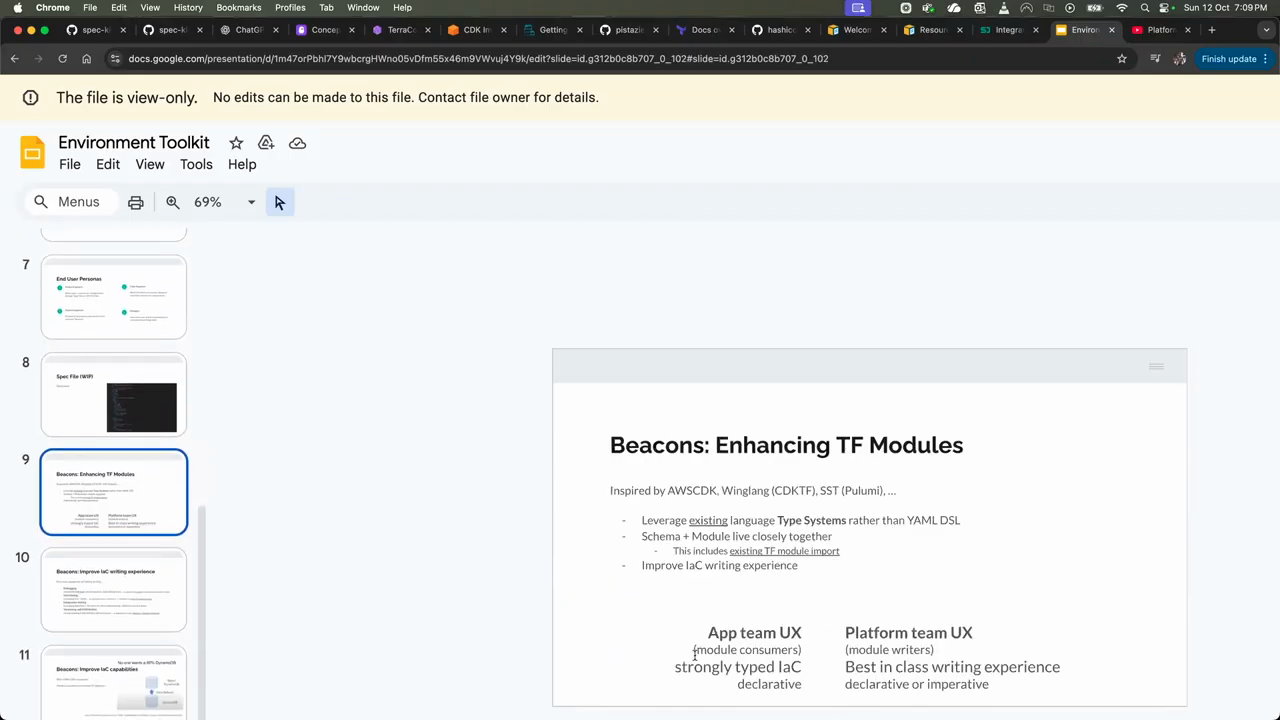
The Philosophy of Modern Platform Teams
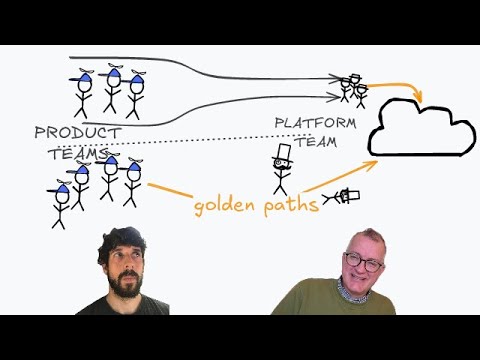
The discussion concludes with a debate on the role of platform teams versus embedded SREs. While some engineers prefer a cross-functional, embedded approach, the reality of large, regulated organizations often necessitates a centralized platform team to handle compliance, auditing, and “zero trust” initiatives. The “golden path” is presented as the ideal solution: the platform team provides standardized, highly-functional tools and guardrails that allow product teams to move quickly without being blocked. platform team’s responsibility is to put in guard rails they’re not the bottleneck they just need to make sure that teams can do what they need This involves moving away from “restricting” access through limited modules and instead focusing on “observing” team usage to extract and share successful patterns. Whether using TypeScript, YAML, or specialized configuration languages like Pkl, the objective remains the same: empowering developers to own their infrastructure while maintaining the security and reliability standards required by the business. The engineers emphasize that platform teams should be “laying the tracks” for product teams, ensuring that the easiest path to production is also the most compliant and stable one.
Model: google/gemini-3-flash-preview