Episode 5: Trunk based infrastructure with feature flags
Published: Wednesday, Nov 12, 2025 • Duration: 68 minutes • Season 1

Download MP3 | Watch on YouTube
https://github.com/vincenthsh & https://github.com/kaihendry/ - two infrastructure engineers talking about Instructure sprawl
00:00 AWS Account organisation https://github.com/kaihendry/actions/blob/main/accounts.json 20:00 System Initiative 29:00 Cloud abstractions are needed 30:40 Danger of clickops 37:31 Labels vs Tags 40:10 Integration points
summarize "https://youtu.be/z6V8fgm7xYY" --timestamps --slides
This discussion between infrastructure engineers explores the complexities of managing AWS at scale, focusing on the evolution from traditional account management to trunk-based infrastructure. The conversation highlights the difficulties of tracking resource sprawl across multiple teams and regions, the trade-offs between different Infrastructure as Code (IaC) tools like Terraform and AWS CDK, and the implementation of feature flags to manage infrastructure changes. They emphasize that as cloud environments grow, the need for robust tagging policies and automated update mechanisms becomes critical to prevent “yak shaving” and technical debt. The best way to control how features get rolled out across your infrastructure is by putting in feature flags.
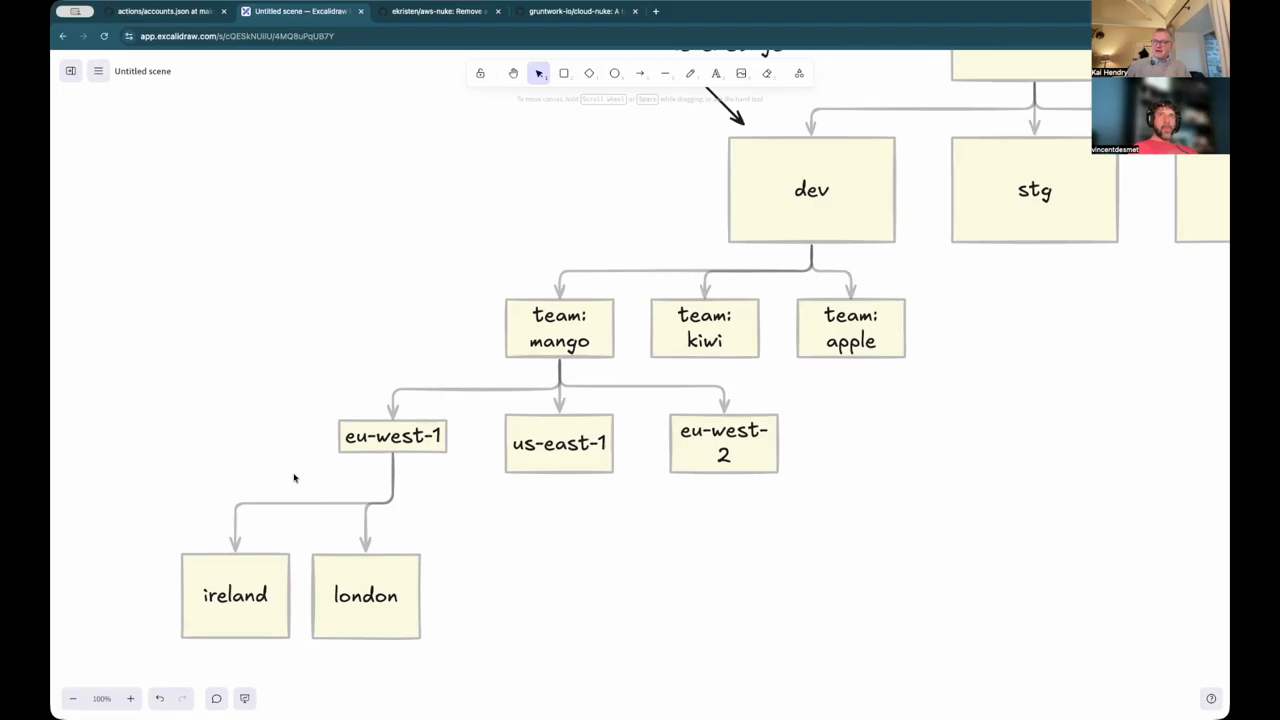
Managing AWS Account Sprawl and Visibility
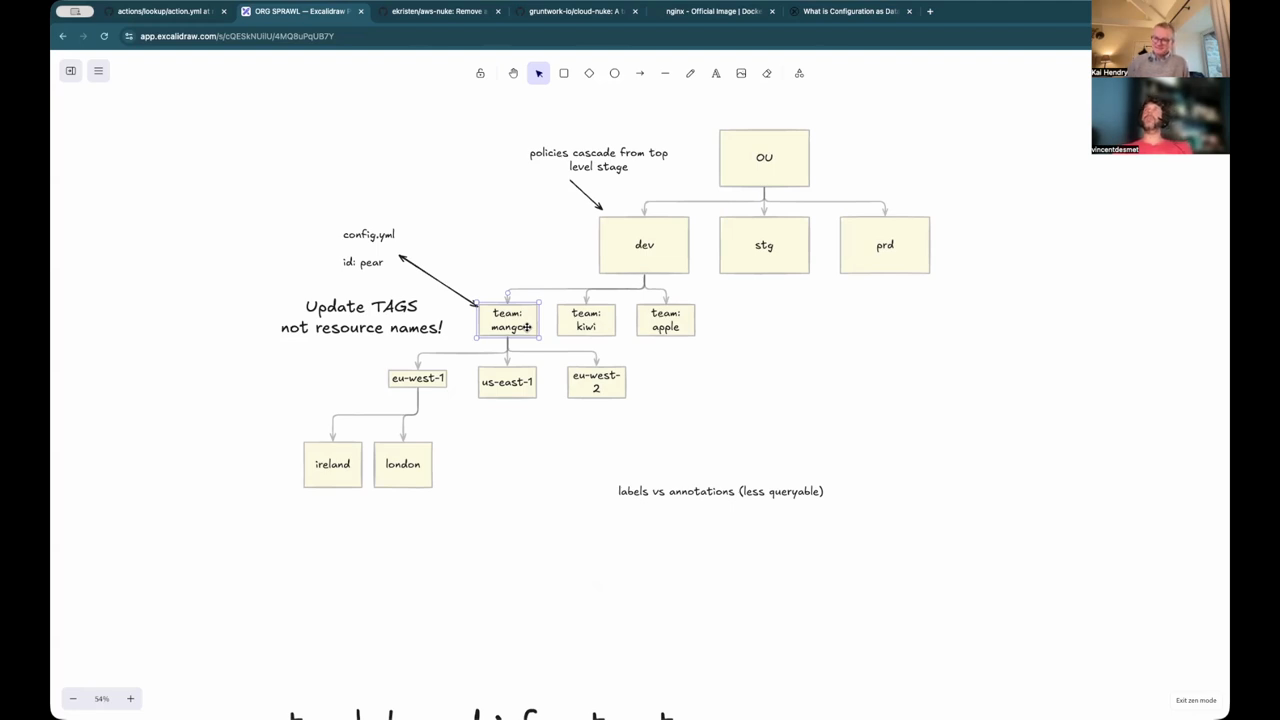
Platform engineers often struggle with visibility into which teams have deployed resources in specific AWS regions. In large organizations, teams like “Team Mango” or “Team Apple” might have deployments in US-East-1, Singapore, or London, often across different accounts for dev, staging, and production. Tracking this sprawl manually is nearly impossible, leading to the use of tools like “the grid” or Terraform Cloud that utilize labels to track state files. Labels allow engineers to query which resources exist in a certain region or belong to a specific team. However, multi-regional Terraform states can complicate this tracking, especially when a single state file manages cross-region resources like VPC peering. The engineers suggest that while separating state by region is a common practice, it can lead to management overhead that requires sophisticated labeling to navigate effectively.
Organizing Accounts by Stage and Security
A significant architectural decision involves whether to organize AWS accounts by team or by environment stage. The engineers advocate for organizing by stage (dev, staging, prod) using nested Organizational Units (OUs) in AWS Organizations. This structure allows security teams to apply specific Service Control Policies (SCPs) at the stage level, which then trickle down to all teams within that stage. For example, non-production OUs can have more relaxed rules, while production OUs have strict guardrails. This approach is contrasted with the “Sam Newman” microservices model where every service and environment might get its own account, which, while secure, introduces massive overhead for peering and account management. To mitigate the cost and clutter of numerous accounts, they discuss using “nuke” tools like AWS Nuke or Cloud-Nuke to programmatically destroy ephemeral environments and return accounts to a reusable pool.
Decoupling Logical and Physical Identities
One of the most common points of friction in infrastructure management is the naming of resources. Engineers often face “push back” when they attempt to use autogenerated or non-human-readable physical IDs because developers who use the AWS console for “click-ops” cannot easily find their resources. However, tying physical resource identities to organizational names (like a team name) is dangerous; if a team is renamed or merged, changing the resource name can be highly disruptive and require resource recreation. The solution is a strict tagging policy where logical identities are managed through mutable tags rather than immutable physical names. AWS Resource Manager can then be used to slice and dice resources across the entire organization based on these tags. This ensures that even if a team changes its name, the underlying infrastructure remains stable while the metadata is updated.
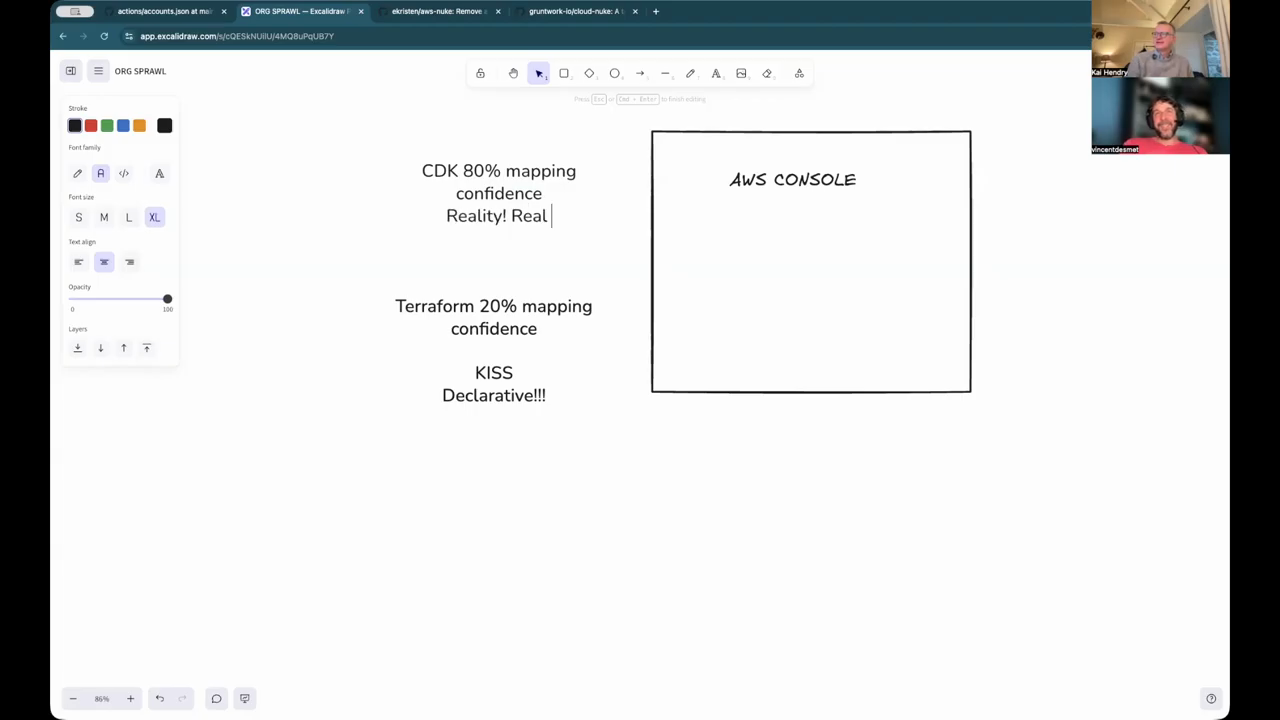
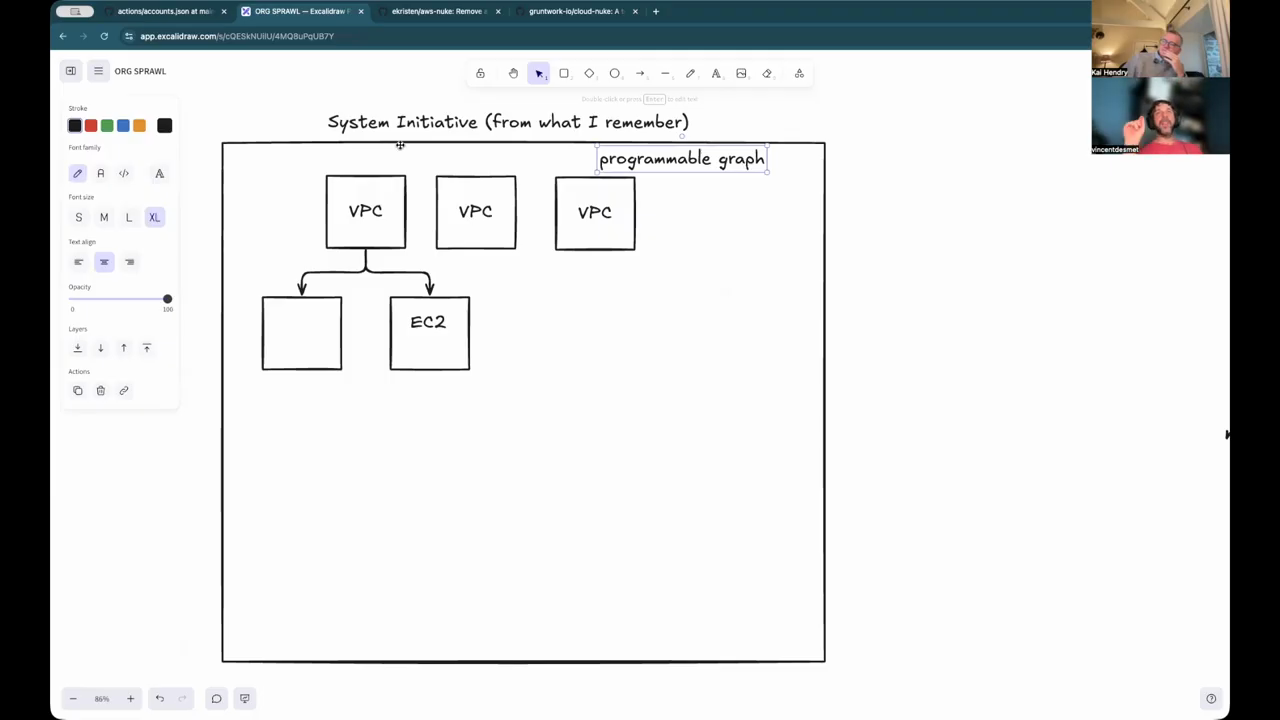
Abstractions and Hidden Infrastructure Dependencies
The choice between Terraform and AWS CDK often comes down to the level of abstraction required. While Terraform is excellent for low-level resource definition, AWS CDK provides higher-level “constructs” that encapsulate common integration patterns, such as automatically creating the necessary IAM roles and policies when an EC2 instance is granted access to an S3 bucket. However, these abstractions can sometimes hide critical details. For instance, a service like ECS might create an underlying S3 bucket that is not explicitly documented, leading to failures if the organization has strict, global bucket policies that deny certain configurations. The engineers also discuss “System Initiative,” which attempts to replace traditional state files with a programmable graph that uses AWS CLI hooks for CRUD operations. While innovative, they note that such tools must have extensive library coverage to be useful, as building every component from scratch is a significant barrier to entry.
Automated Update Mechanisms and Registries
In a multi-team environment, keeping infrastructure configurations up to date across hundreds of repositories is a major challenge. Some organizations use a central “integration registry” (often a large JSON file or SSM Parameter Store) to track connection points between services. To propagate updates, they discuss two main models: “pull” and “push.” The pull model uses tools like Dependabot or Renovate to create pull requests in team repositories, but this can lead to PR fatigue and stale configurations if teams do not merge them promptly. Alternatively, a “push” model involves a central script (like a “distribute.py” Python script) that directly commits updated workflows or configurations to team repositories. While more aggressive, the push model ensures that critical security or platform updates are applied immediately across the entire organization, preventing teams from falling behind on the platform’s evolution.
Trunk Based Infrastructure with Feature Flags
The engineers propose a “trunk-based” approach to infrastructure where modules are not pinned to specific versions but instead point to the latest version (head) in a monorepo. To manage the risk of this approach, they implement feature flags within Terraform variables. Trunk based development on my IC with feature flags… we always have everything on head. This allows a platform team to roll out a change (like a database migration) by first deploying the code with the feature flag disabled. They then toggle the flag in dev, then staging, and finally production. This workflow, often managed by tools like Atlantis, ensures that every change is planned and tested against all environments simultaneously. If a change would break production, the Atlantis plan will fail, blocking the PR. This methodology eliminates the “version hell” where some teams are stuck on years-old modules, ensuring the entire organization moves forward on a single, unified infrastructure path.
Model: google/gemini-3-flash-preview