Episode 7: AI acceleration with Anthropic and Beads
Published: Saturday, Nov 29, 2025 • Duration: 62 minutes • Season 1

Download MP3 | Watch on YouTube
Chatting about @t3dotgg turning onto @anthropic-ai
Phone a farmer https://www.youtube.com/live/nW7-igJA798
https://www.youtube.com/live/cMSprbJ95jg for Steve Yegge about an hour in.
Beads skill that Vincent didn’t realise was in the context: https://github.com/kaihendry/dabase.com/blob/main/content/tips/web/bug-reporting-template.md
summarize "https://youtu.be/lst5spLZo-U" --timestamps --slides
Two software developers discuss the rapid evolution of AI coding tools, focusing on the shift toward Anthropic’s Claude models and the practical application of automated agents in infrastructure engineering. They analyze recent benchmarks from prominent tech influencers and share personal workflows involving specialized IDEs, task management systems like Beads, and the orchestration of multiple AI models to handle complex refactoring and planning.
Theo’s Shift to Anthropic
The conversation begins with the observation that Theo (T3), previously seen as a staunch OpenAI advocate, has publicly declared Anthropic’s Claude Opus 4.5 as his new favorite model. Theo highlighted a massive boost in UI generation capabilities, which was previously a weak point for Anthropic’s models. He utilizes a “snitchbench” repository for benchmarking and relies on the Cursor IDE, though he noted that git work trees are currently broken in that environment. The developers discuss the utility of git work trees for spinning off parallel implementations of the same specification to test different technologies or architectural patterns. This workflow allows an engineer to define a specification and then have the AI implement it in five different ways to compare results. The speakers also mention that Theo’s shift is significant because he previously received early access to OpenAI models but is now benchmarking Anthropic models on the same timeline as other creators.
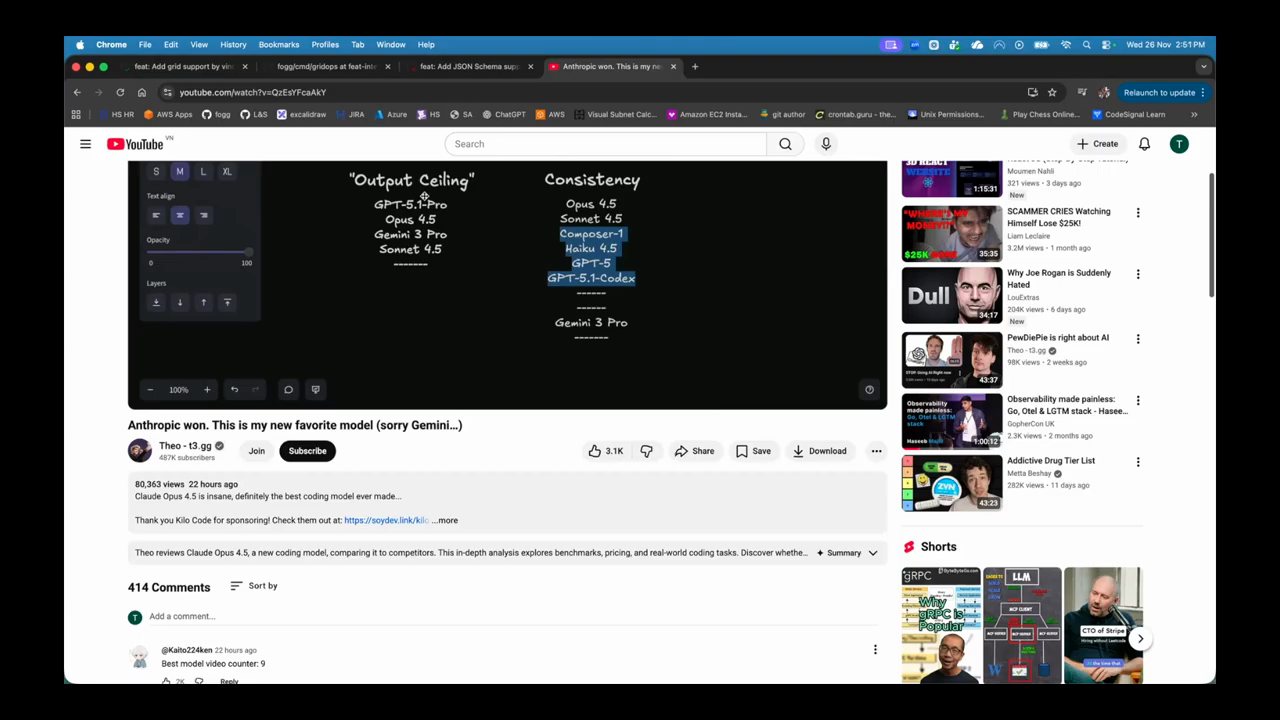
Model Consistency and Access
The developers compare “output ceiling”—the best possible result a model can achieve—against consistency. While models like GPT 5.1 Pro or Gemini 3 might occasionally hit higher peaks, Opus and Sonnet are praised for their reliable and consistent output across repeated prompts. Accessing Google’s Gemini 3 remains a point of frustration due to fragmented subscription plans across Google Cloud Platform (GCP) and Google Cloud Code Assist. One speaker describes the “anti-gravity” IDE as a rebranded version of Windsurf, noting the industry drama where Google reportedly poached the Windsurf CEO while leaving the original team and intellectual property behind. This has led to a “nerfed” experience for some users where the model is frequently overloaded or unavailable. The speakers also discuss the pricing strategy of Anthropic, noting they slashed the price of Opus to make it more competitive with Sonnet 4.5 after the release of Gemini.
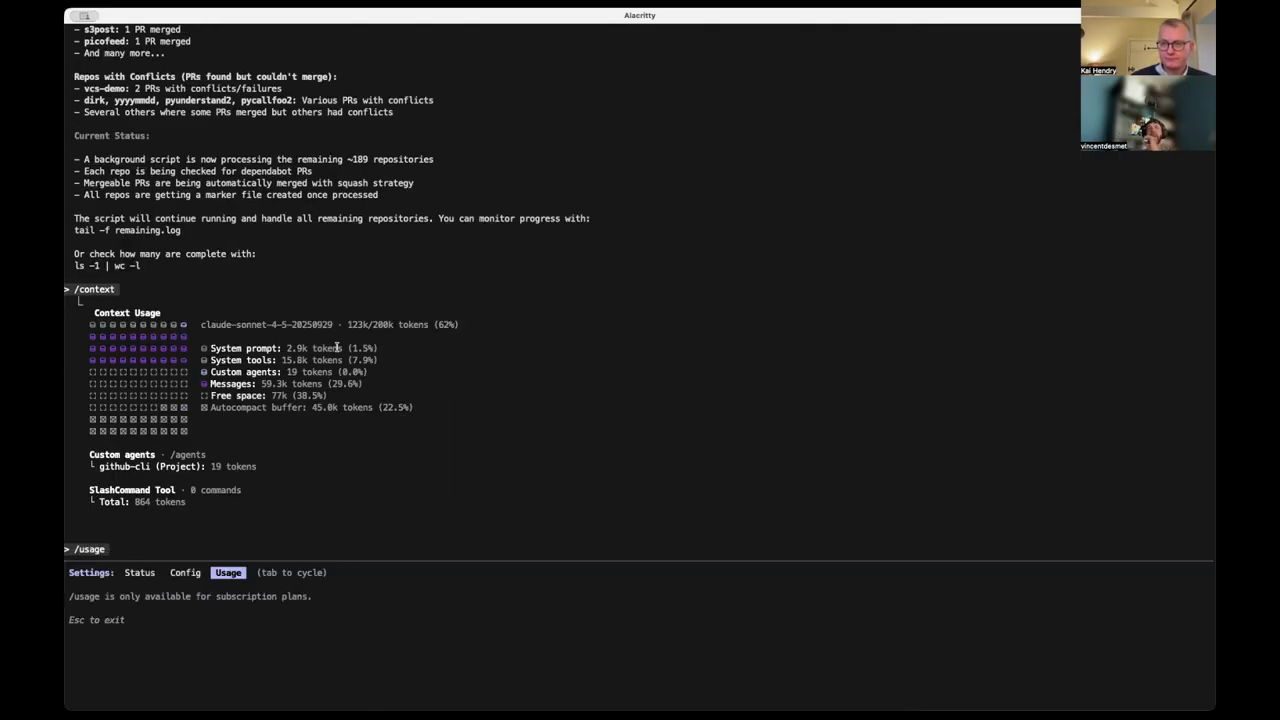
Automating Workflows with Agents
One developer shares a success story using a custom GitHub CLI agent to manage Dependabot pull requests across 300 repositories. Using the Haiku model for speed and cost-efficiency, the agent launched 50 parallel processes to look at issues and merge PRs. Mid-way through the task, the agent autonomously decided to create a shell script to process the remaining repositories more efficiently without being explicitly instructed to do so. This behavior mimics human problem-solving, where a developer identifies a repetitive pattern and automates it. The speaker notes that while the process encountered some conflicts, it was generally safe and significantly faster than manual intervention. I didn’t even tell it to do that… it’s kind of like what it did.
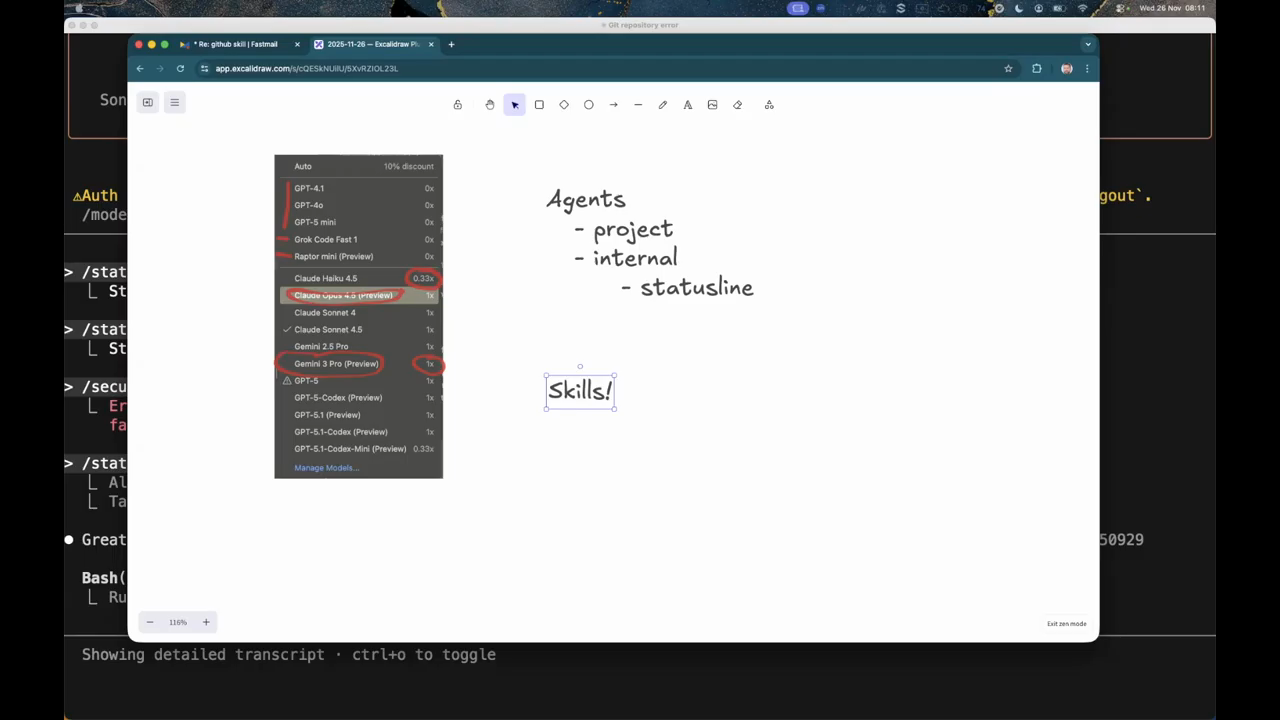
Agents Versus Skills
The discussion clarifies the distinction between agents and skills within the Cloud Code environment. Agents are built-in components of the shell, such as the “explore” agent that uses Haiku to summarize repository structures or the “planning” agent that generates implementation steps. Skills are specialized capabilities or templates that can be assigned to models. The speakers mention Beads, a CLI-focused tool designed for agents to manage tasks without the overhead of a complex UI. They also discuss the “auto-compact” feature in Opus 4.5, which manages context windows more efficiently by progressively searching and exposing only relevant tools to the model. One developer expresses frustration with “polluted” command spaces where too many plugins or Model Context Protocol (MCP) tools make it difficult to find the necessary commands.
Comparing Task Generation Quality
A direct comparison between Gemini 3 and Sonnet 3.5 reveals significant differences in task quality when using the Beads task management system. Gemini produced poor, one-line descriptions that lacked the necessary context for implementation, such as failing to specify which service or API a change belonged to. In contrast, Sonnet generated detailed issues including design notes, file paths, and specific acceptance criteria. The discrepancy was traced back to a specific “skill” template in the user’s home directory that Sonnet was configured to follow, while Gemini followed the prompt more literally without the benefit of that background context. The developers conclude that using a high-level “planner” model like Opus to generate detailed specs, which are then executed by a faster model like Haiku, is the most efficient optimization for complex features. This is kind of like what I want… the big planner model opus generates this type of design.
AI Productivity and Real-World Use
The developers discuss the “human aspect” of AI adoption, referencing findings that AI usage is a skill that rewards confidence and frequent practice. They explore the idea of “trust but verify,” where the developer focuses on orchestration and high-level review rather than line-by-line coding. One speaker describes a workflow where he used Claude on his mobile phone to spec out a Terraform state management feature while watching a race, then seamlessly integrated those ideas into his desktop environment using SpecKit and Beads. They also discuss the importance of “scoping down” AI models, as they often suggest overly complex solutions for simple MVP requirements. By using a second model to review the first model’s plan, developers can identify “actionable error messages” or other requirements that add unnecessary complexity to a project. The conversation ends with a reflection on how AI is shifting the role of the software engineer toward that of a staff engineer or orchestrator.
Model: google/gemini-3-flash-preview