Episode 15: Ralph Wiggum, Gas town, Playwright right, Omarchy & Skill issues
Published: Wednesday, Jan 7, 2026 • Duration: 60 minutes • Season 1

Download MP3 | Watch on YouTube
https://x.com/mattpocockuk/status/2008200878633931247
https://steve-yegge.medium.com/the-future-of-coding-agents-e9451a84207c https://github.com/steveyegge/gastown
https://github.com/kaihendry/skills
00:00 Ralph Wiggum 01:37 Gas town 13:21 Testing 16:26 Playwright demo 33:41 Ralph Wiggum memes 36:37 Omarchy 41:11 Skills for AI
summarize "https://youtu.be/o-NUs1isBp8" --timestamps --slides
This clip is a technical conversation that jumps between memes, agent orchestration, LLM-driven testing, and developer tooling. The hosts use the Ralph Wiggum meme as a framing joke to discuss why simple looping patterns can outperform heavy orchestration, then dig into Steve Yegge’s Gastown design choices and iterations, a live demo of LLM-generated Playwright end-to-end tests, token and cost tradeoffs when models send large page snapshots, and higher-level debates about who will adapt to agent-first workflows (engineers, product people, or curious hobbyists). The tone mixes practical demos (a working Playwright test suite generated by an LLM) with design lessons drawn from multiple Gastown iterations and the limits of current “skills” and context windows.
Ralph Wiggum as shorthand for looping agents
The hosts open by awarding the “Ralph Wiggum” meme status to a class of agent workflows that rely on simple loops rather than heavy orchestration. The meme (“I’m in danger.”) is used to mock quick, looped approaches that can be surprisingly effective because “the models have become so good.” They contrast lightweight looping with more feature-rich orchestrations and link that intuition to Steve Yegge’s Gastown posts, which document multiple design passes and tradeoffs in agent naming, components and communication patterns. “I’m in danger.” “the models have become so good.”
Gastown, naming, and orchestration tradeoffs
They discuss Steve Yegge’s two posts: an initial Gastown announcement (noting a $600/month running cost) and a longer second post that explains iterations (Python → VC → Golang, several workshops). The conversation highlights problematic terminology (bcats, scrapyard, towns) and why naming matters: engineers want concrete terms (OCR scanner microservice) rather than obscure project handles. Two orchestration approaches are compared: giving each agent isolated git worktrees/branches and resolving merge conflicts later versus sharing a single filesystem with coordination primitives (file reservations/locks) to avoid conflicts upfront. The hosts note Gastown’s mail/MCP was conceived by non-engineers and argue that non-engineering perspectives can surface simpler, effective coordination models.
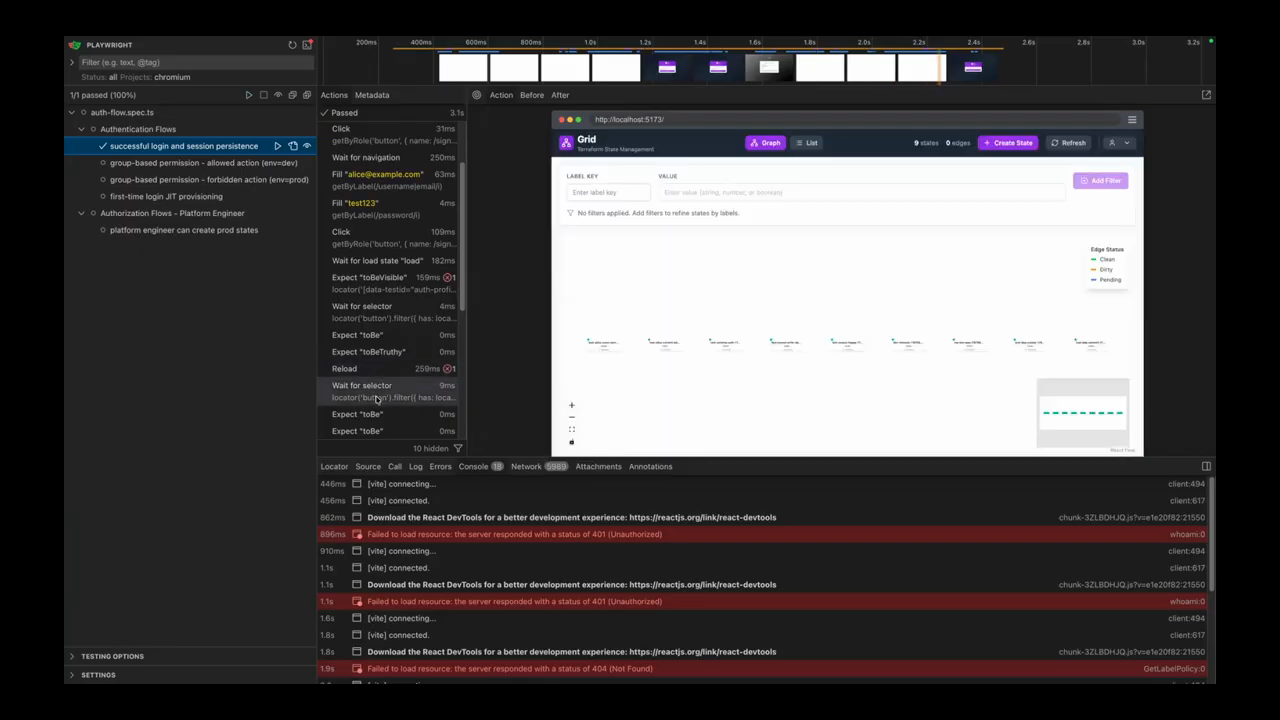
Playwright demo: LLM-generated end-to-end tests
One host demos an end-to-end Playwright test suite that was generated entirely by an LLM (no handwritten test code). The test setup is ~170 lines; it bootstraps containers, creates test users (Alice, platform user, new user with no groups), registers roles in the API, then runs UI flows (login, refresh, assert session persistence). Tests are launched in parallel: separate Chrome instances (non-headless) run multiple workers simultaneously. A simple successful login-and-refresh run completed in about 3 seconds in the demo. The script waits for selectors (test IDs) and verifies UI states; failure modes are exposed with browser console output and screenshots. The demo emphasizes that an LLM can produce executable Playwright scripts that perform complete E2E checks and environment setup.
Debugging with page snapshots, huge prompts, and token costs
When a test fails because an element can’t be found, Playwright produces a structured page snapshot (a YAML-like DOM skeleton) plus encoded screenshots; feeding that snapshot to an LLM produces a comprehensive diagnostic. The demo showed an automatically generated LLM prompt that included the page structure and a large failure trace — the prompt reached a few hundred lines (~300 lines reported) and included the YAML snapshot and context. Pasting that snapshot into a fast cloud model immediately identified a changed test ID as the cause. The hosts highlight two costs here: (1) token bloat from sending large encoded images and page dumps (Playwright’s MCP approach can send B64 screenshots and structural data that are very large), and (2) real-money API wallet surprises — one anecdote described a paid subscription where enabling “extra usage” burned a monthly $20 allowance quickly. The overall point: Playwright’s script-based approach bundles logic server-side (smaller chat turns) while snapshot-based MCP-style interactions can balloon token usage; both approaches have tradeoffs for debugging and cost.
Model speed vs quality, tooling defaults, and small platform anecdotes
They contrast two model behaviors: very fast, looped cloud-code workflows that may require repetition and external loops versus slower models (GPT-5.2 in discussion) that internally iterate and produce more correct outputs. This is framed as a speed/quality tradeoff: snappy models that need orchestration loops versus slower-but-deeper reasoning. The hosts also note ecosystem moves: one distro/toolchain (Omari) ships with an open-code CLI agent by default and bundles cloud-code/agent tooling to simplify the dev experience; installer anecdotes claim very fast installs (one host reported a 3-minute install, another 6 minutes 20 seconds), and emphasis on theming and polish as a user-acquisition lever. These details illustrate how developer ergonomics and default tooling choices shape who adapts to agent workflows.
Skills, context-window limits, roles, and the future of agent tooling
They close with meta issues: “skills” can become redundant as models learn common CLIs (example: models eventually know how to run GitHub CLI without explicit skill injection), but skills still capture small platform-specific traps (e.g., GH pager behavior, commit checks). Context degradation matters: hosts cut off tasks before the tail of the session to avoid “dumb” behavior when remaining context is low. They debate who will adapt: engineers, product owners, or hobbyists—concluding it’s about who invests time to get reps and learn the new patterns. Steve Yegge’s Gastown is singled out as an example of iterative design: several passes (three or four iterations) produced a flow that agents now use intuitively, and because LLMs will be retrained on public repos, tools like Gastown and Beats will only become easier for models to use over time. The clip closes with a mix of technical demos, concrete operational caveats (costs, token bloat, CI flakiness observed in a repo), and practical advice about keeping goals narrow so LLM-driven agents don’t drift.
Model: openai/gpt-5-mini