Episode 24: AI's broken mirror
Published: Thursday, Mar 12, 2026 • Duration: 66 minutes • Season 1

Download MP3 | Watch on YouTube
https://dabase.com/podcast/ for a summary
summarize "https://youtu.be/glx4mkYRt7U" --timestamps --slides
This conversation explores the evolving landscape of AI-assisted software engineering, focusing on the transition from simple chat interfaces to sophisticated agentic workflows. The speakers discuss the challenges of maintaining context in large-scale projects, the necessity of team alignment when using AI agents, and the technical nuances of managing infrastructure through tools like AWS CDK and Open Policy Agent. They emphasize that while AI can accelerate development, human expertise remains critical for deterministic validation and architectural integrity. The discussion highlights the tension between “vibe coding”—a fast, conversational approach—and formal spec-driven development, which ensures that AI-generated changes remain maintainable and aligned with team standards.
Capturing AI Decision Logs
The speakers address the difficulty of sharing AI sessions within a team, noting that full transcripts are often too long and messy to be useful. They propose a more structured approach called session capture, which identifies key decisions and information to accompany code changes. One implementation involves a framework that hooks into git commits to capture the “delta of messages” from the AI agent that led to that specific change. By tagging these messages with a commit ID, developers can roll up the prompts and reasoning behind every modification. This allows team members to understand not just what code was changed, but the specific instructions and edge cases the AI was considering at the time. The goal is to convert raw session data into a searchable knowledge base rather than storing large, unorganized blobs of text.
Progressive Disclosure in AI Skills
When building tools for AI agents, the speakers emphasize the importance of “progressive disclosure” to prevent the model from being overwhelmed by too much information at once. They describe a process of breaking down large onboarding guides and documentation into smaller, specialized modules like architecture, tech stack, and API docs. In one technical example, a developer streamlined a complex CLI by converting various bash and Python scripts into a single binary with subcommands. These subcommands act as “skills” that the agent can discover as needed. A notable anecdote involves an agent encountering a failure with a documented REST API for a project management tool. The agent was able to “spy” on a browser session, identify the actual endpoint being used by the web application, and update its own skill set to use the functioning, undocumented API instead of the broken official one.
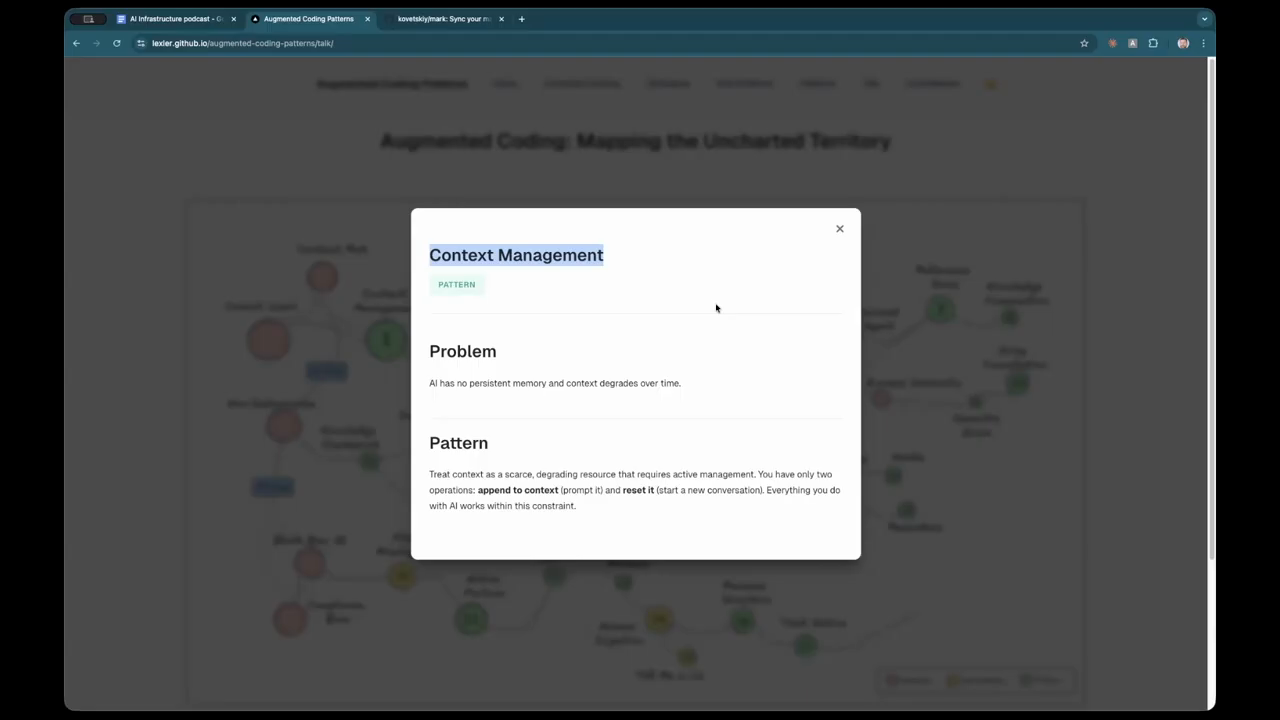
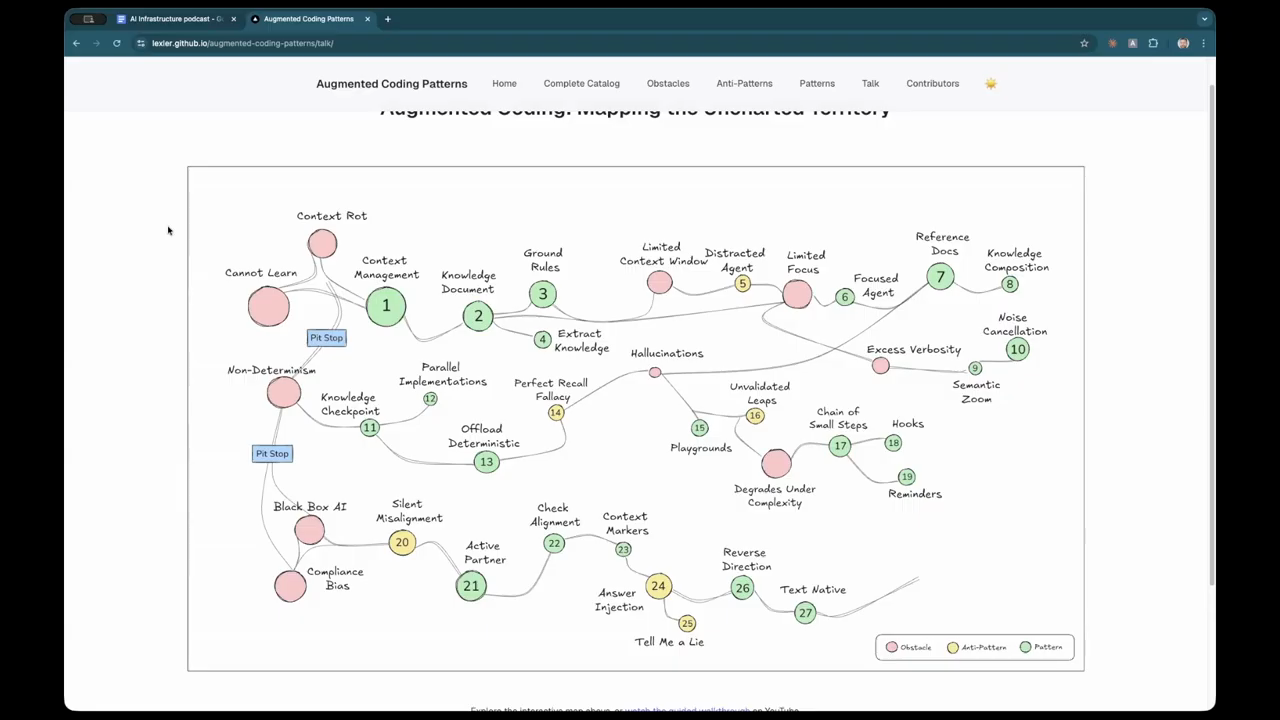
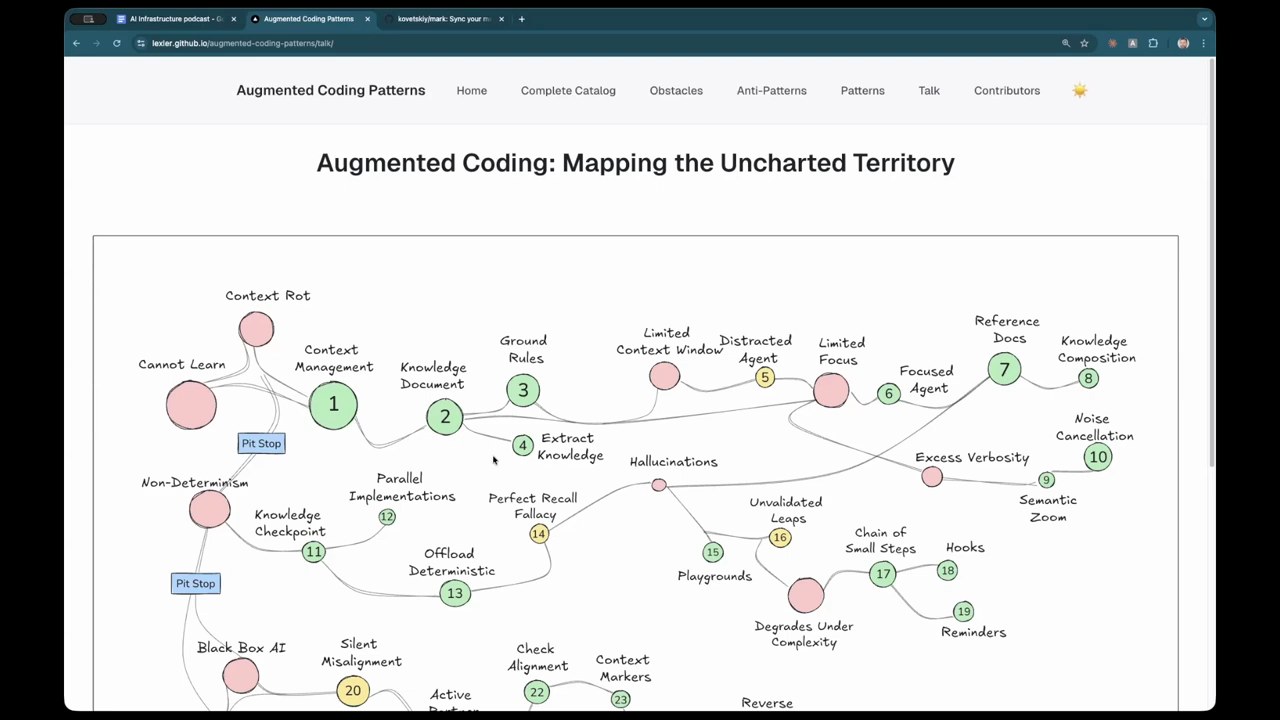
Managing Context Rot and Token Limits
Despite the availability of models with 1-million-token context windows, the speakers observe that agents still suffer from “context rot,” where they lose track of fine details as a conversation progresses. They suggest that context should be treated as a scarce and degrading resource. To manage this, they use “checkpoints” where the model is asked to provide a detailed progress update and a summary of completed work items. This summary can then be used to start a fresh session, clearing out the “noise” of previous debugging attempts or failed explorations. They also discuss the use of a “constitution”—a set of ground rules that the agent checks itself against after certain phases of work to ensure it remains aligned with project standards. This prevents the agent from drifting into inefficient patterns or ignoring established architectural rules during long-running tasks.
Vibe Coding Versus Spec-Driven Development
The speakers define “vibe coding” as a conversational, exploratory way of working with AI that is highly effective for simple bug fixes or one-line changes. However, they warn that this approach can lead to “slop” when applied to complex features. For larger tasks, they advocate for a “mini-waterfall” approach: researching technologies, creating a plan, generating a task tree, and establishing clear acceptance criteria before the agent begins writing code. This ensures team alignment and prevents the agent from creating unnecessary dependencies or over-complicating the solution. They argue that the role of the human engineer is shifting toward quality control and deterministic validation, requiring deep expertise to spot when an AI is heading down a sub-optimal path. The division is simple, deterministic computation and probabilistic reasoning, they are complementary, the part between them is where the work happens. It takes experience to realize so nuance about what we do. There is no like clean cut way, which makes it really painful.
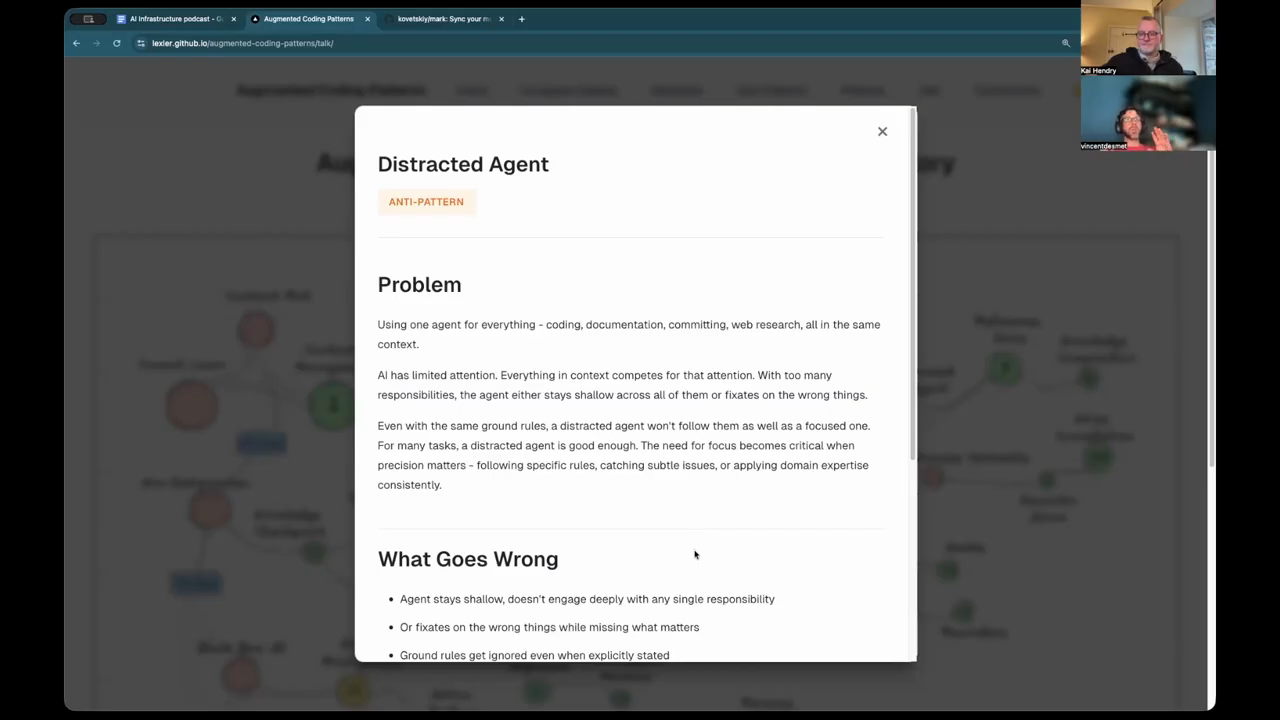
The Broken Mirror of AI Repetition
A recurring frustration discussed is the “broken mirror” effect, where AI-generated content or summaries repeat the same core ideas multiple times with only slight variations in phrasing. This fragmentation makes it difficult to distill information into a concise, actionable format. To combat “distracted agents” that try to do too much at once, the speakers mention a new interface feature that allows a user to suspend an agent’s current task to ask a side question. This “by the way” functionality prevents the side conversation from polluting the main task’s context. They also touch on the rise of “AI slop” on social platforms, where long, repetitive walls of text are easily identified by human intuition due to specific linguistic markers like the overuse of em-dashes or a lack of original insight.
Infrastructure Compliance and Programmatic Validation
The final segment focuses on managing large-scale infrastructure as code, specifically using the AWS Cloud Development Kit (CDK). A common problem in large organizations is the divergence of “constructs”—reusable infrastructure patterns—as they are copied and modified across different teams. The speakers discuss using “aspects,” which are programmatic visitors that can inspect every node in a construct tree during the synthesis phase. Aspects can be used to enforce security policies, such as ensuring that all EC2 instances use a specific metadata service version, or to validate that resources are tagged correctly for cost tracking. They also explore the use of Open Policy Agent (OPA) as a rule-based matching engine to validate terraform plan files, ensuring that infrastructure changes meet technical compliance standards before they are deployed to production.
Model: google/gemini-3-flash-preview