Episode 18: AI Engineer Anti-Patterns + more
Published: Sunday, Jan 25, 2026 • Duration: 89 minutes • Season 1

Download MP3 | Watch on YouTube
I show https://clawd.bot/ & WhatsApp integration.
We touch how type checking is not done enough in Python https://docs.astral.sh/ty/
We speculate what’s the “Next big thing” in Infrastructure… better state management with https://stategraph.com/?
https://handy.computer/ dictation (speech to text) is shown
We try capture what the the AI lifecycle looks like right now.
Show notes: https://docs.google.com/document/d/1zoc-0L1o1Cyxtgatb9fN_ZGBGbshZIb9BTzwEj0C4Gc/edit?usp=sharing
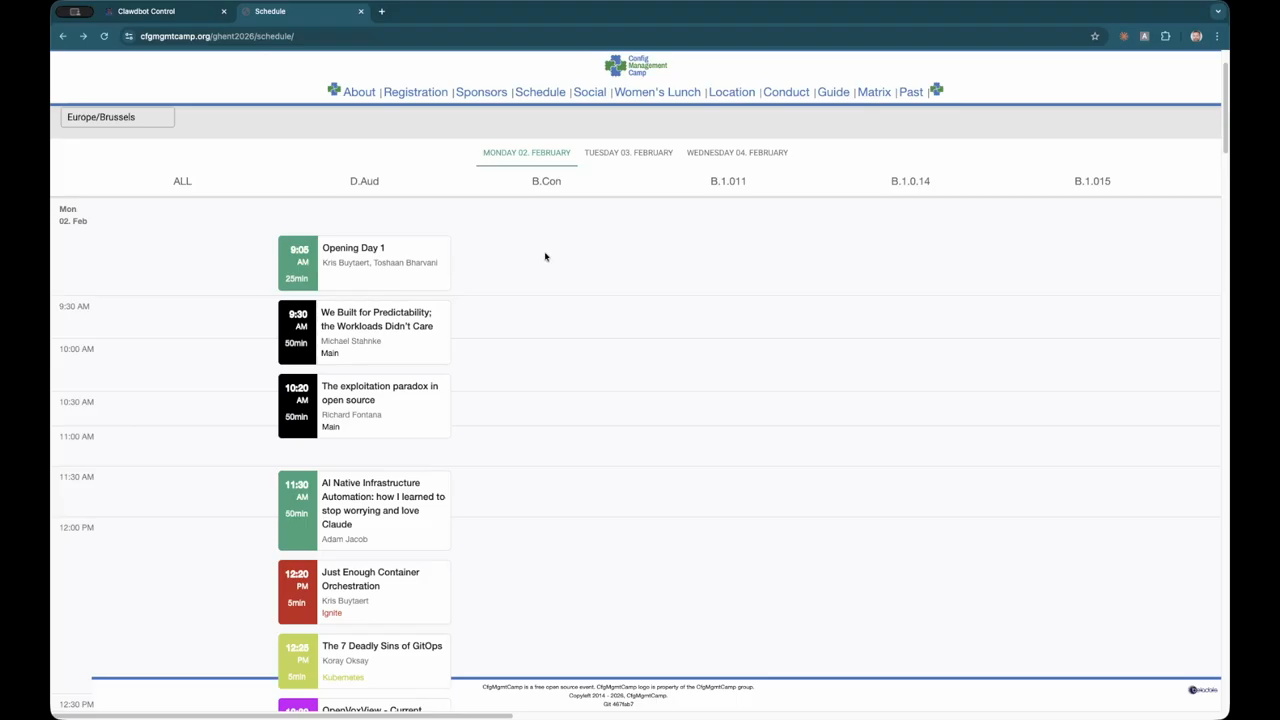
Kai will be at https://fosdem.org/2026/ & https://cfgmgmtcamp.org/ghent2026/ next week … say hello if you see me!
summarize "https://youtu.be/0lQTnRKHVdM" --timestamps --slides
Conversation between two engineers touching infrastructure tooling, a hosted assistant integrated into messaging, the role of type checking in infra, speech-to-text experiments, spec-driven development and tests, and repo hygiene debates.
CDK fork pre-release and multi-language tests
They prepared a pre-release of a renamed CDK fork with a full green test suite and published packages for multiple runtimes; integration tests passed for Java, .NET, Go and Python. Packaging work included updating build settings (Maven/NuGet equivalents) so consumers can pull pre-release artifacts. The hosts note that while the CDK ecosystem exposes bindings to many languages, most adoption concentrates on TypeScript and Python, and non-JS runtimes often run slower because the multi-language kernel launches a Node subprocess as a bridge, adding latency compared with native JS execution. They also discussed how an upstream infra tool moved internal APIs behind an “internal” package in a recent major version, which broke previous direct reuse patterns and increased the friction for language bindings.
Hosted assistant on messaging and cron prompts
One engineer demoed a hosted assistant they deployed to a small server and integrated with a messaging app so a household group can message the assistant (text, images) without launching a separate app. They run scheduled prompts (cron-style) that ask the assistant to check URLs for weather warnings or announce upcoming events, and link the assistant to a web-search API to improve internet lookups. The deploy ran fine on a low-power single-board computer, and the presenter used a phone as an external camera for demos.
Type checking as a shift-left safety net
They argued that strong type checking is “absolutely critically important for infrastructure” because it provides fast, local feedback and prevents novel runtime failures; a Python type-checker was used to sanity-check code during a large rename, avoiding expensive synth runs. The discussion contrasts a types-first CDK approach (which leverages TypeScript-style schemas and composable constructs) with the dominant state-based infra tool that exposes weaker schema validation at runtime. The hosts explained that many orgs build private, strongly typed libraries around cloud services to get consistent platform interfaces, and that a network effect is required to make such libraries widely useful; one pragmatic path is automating porting between high-level typed constructs and state-based configs. They also described alternatives to monolithic state locking, where a “state graph” or row-level locking over resources can decompose state operations to reduce contention and enable finer-grained applies.
type checking uh is absolutely critically important for infrastructure
Dictation, editing, and prompt size trade-offs
They tested a speech-to-text tool for dictating prompts and notes, noting it captures literally everything (stutters, mid-sentence corrections) and that an additional AI pass can clean and summarize those transcriptions into usable prompts or prose. The hosts warned that larger prompts and excessive context can worsen AI output quality, so they favor concise, precise inputs over huge context dumps. Practical workflow: dictate → run a cleanup/edit pass with the model → use the cleaned prompt for planning or code generation.
the bigger the prompts the the more context you have the the worse sort of experience you have with AI.
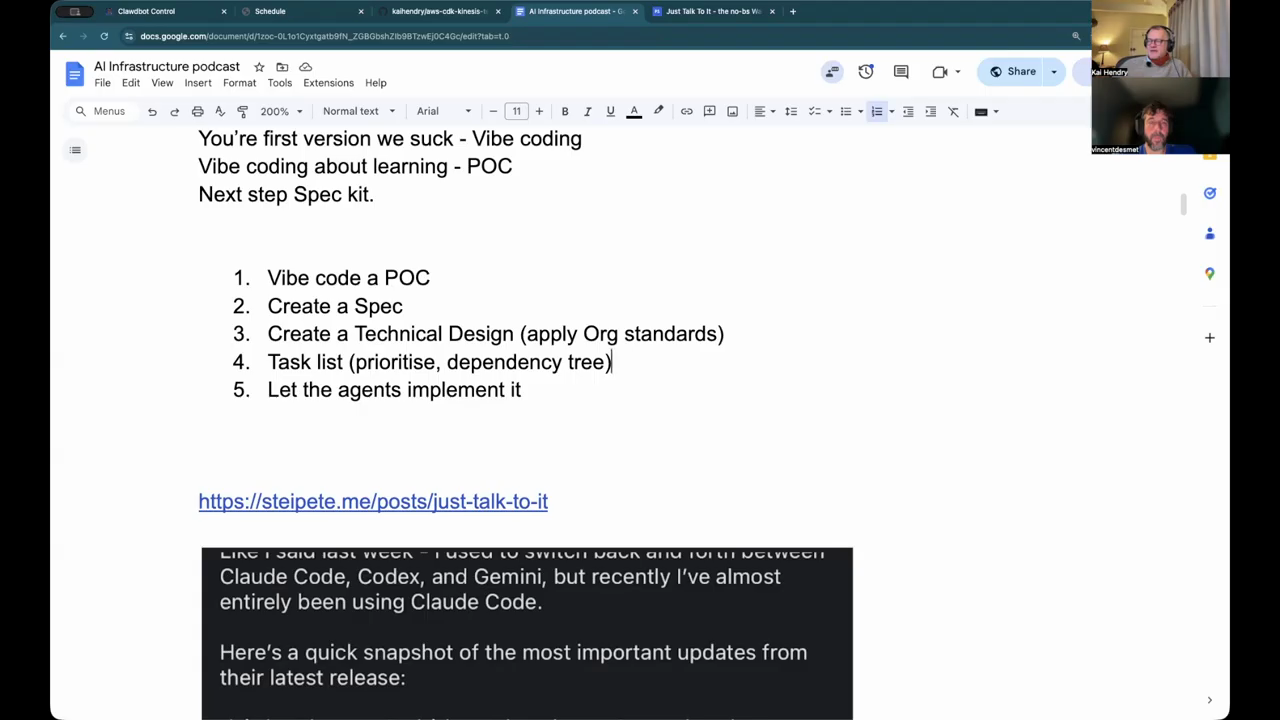
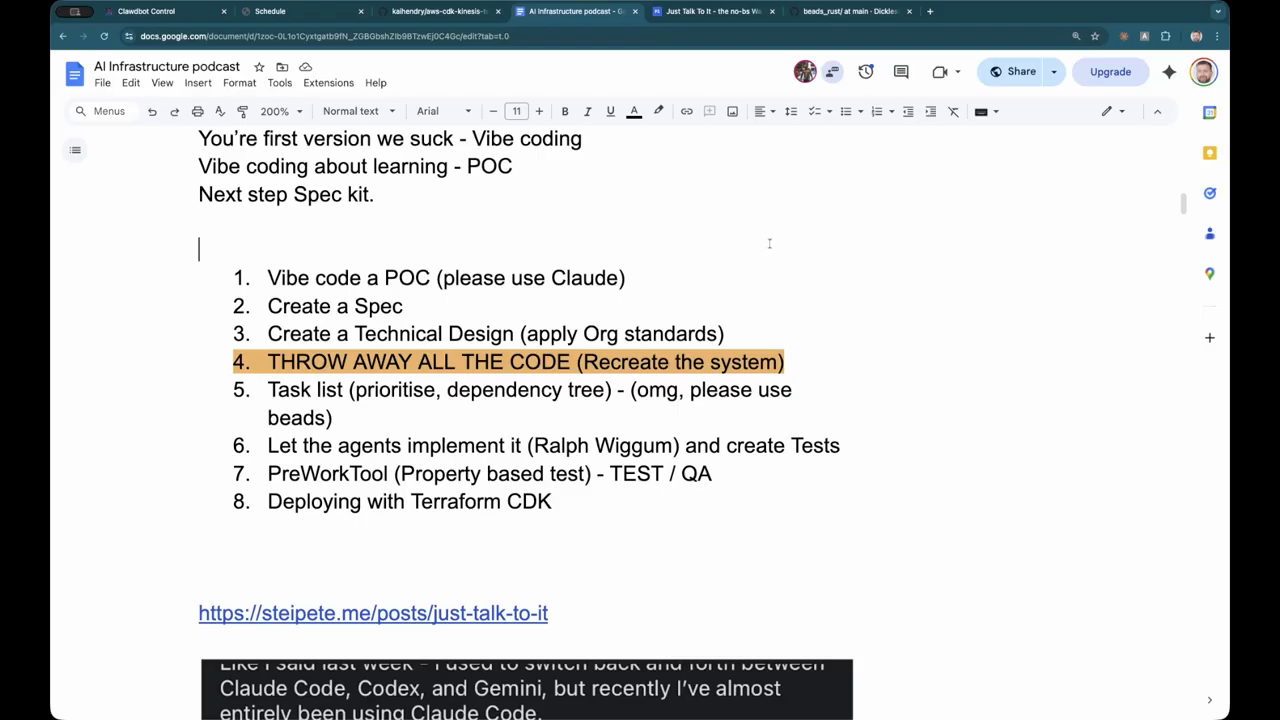
Spec-driven flow, VIP coding, and test generation
They outlined a two-phase delivery model used by an organization: phase one is human-led specification (requirements, acceptance criteria, steering documents) and phase two lets agents implement tasks once validation rules are in place. A spec-driven tool generates a design, extracts a task list (required vs optional), and can represent dependencies so teams can focus on a minimal viable slice before expanding. The hosts discussed model-selection trade-offs (use a higher-quality model for planning, a cheaper model for code generation to save cost) and described automated test generation: the design phase can produce machine-parsable test descriptions so agents can generate property-based tests or other automated checks from explicit “always/never” rules, increasing confidence in generated work.
Repo hygiene, AI-managed repositories, and community reactions
They debated what constitutes repo hygiene: one view is human-readable structure and clear tooling; the other is that if an AI agent has the skills, rules and steering docs to iterate reliably, that repository is “hygienic” enough. A social-media post mocked a project as “AI slop” after an acquisition, which sparked reactions and highlighted how quickly public commentary can misread agent-driven repo artifacts. The episode closes with practical notes: the speaker plans to cut the CDK fork pre-release, attend infrastructure conferences, and keep iterating on integrations, while acknowledging the ongoing trade-offs in tooling updates, environment fragility, and the costs of running models and inference.
Model: openai/gpt-5-mini