Episode 23: Validating AI output & Refactoring Infrastructure
Published: Monday, Mar 9, 2026 • Duration: 35 minutes • Season 1

Download MP3 | Watch on YouTube
Show notes: https://docs.google.com/document/d/1zoc-0L1o1Cyxtgatb9fN_ZGBGbshZIb9BTzwEj0C4Gc/edit?tab=t.0
https://dabase.com/podcast/ for a summary
summarize "https://youtu.be/5CIEYL5HzZI" --timestamps --slides
A freewheeling engineering conversation that starts with a glasses anecdote and quickly moves into practical ways to validate AI-generated code, tighten CI/CD, and refactor infrastructure without causing resource churn; topics include model choices (Claude vs GPT variants), deterministic checks around AI output, Docker image pinning and digest problems, SonarQube and vendoring, personas/multi-agent prompts, moving docs from Confluence to Markdown for agent friendliness, and the differences between AWS CDK and CDK-TF (assets, L1/L2 constructs, and logical ID fragility). The hosts stress building validation harnesses before letting AI edit code and give concrete examples: a PR error using “env” versus “environment”, Docker buildx 0.19 versus 0.26 mismatches, “Wow, I can see everything clearly now.”, and “it’s hard to let AI go wild on that code base.”
Models, versions, subscriptions
One host explains he unsubscribed from one service after the Department of War situation, was offered a free month, and notes community chatter that GPT 5.4 (with codecs/fine‑tuning integrated) is being hailed as better for coding while model naming—5.2, 5.3, 5.3 codecs, ultra-think—has confused users, which motivates picking a single reliable model like Claude for some teams.
Trust, deterministic checks, and CI
They recount a concrete failure where an AI-generated PR used “env” instead of “environment”, reviewers missed it, and stress that CI/CD tools (linters, pre-commit hooks, test harnesses) and local reproductions (Ubuntu Docker VMs) are the correct way to make AI outputs deterministic rather than trusting human eyeballs alone, while also describing Docker immutable digest pinning and the pain of keeping digests up to date.
Vendoring, SonarQube, and makefiles
A vendored install script produced 32 SonarQube issues and forced discussion about allow‑listing versus updating each vendor bump, and they illustrate how makefile targets are a simpler, deterministic pattern compared to the phony targets AI suggested, noting Opus 4.6 produced unnecessary makefile complexity and that knowing Makefile semantics can catch AI mistakes.
Personas, spec ledgers, and docs
They recommend running problems through multiple persona agents (business analyst, database designer, QA engineer) to cover perspectives, discuss spec ledger features vs recent Anthropic config announcements (scheduling/config sharing), and describe a push to migrate docs from Confluence to Markdown plus a Golang CLI skill to make repositories “AI ready” and easier to reference from agents.
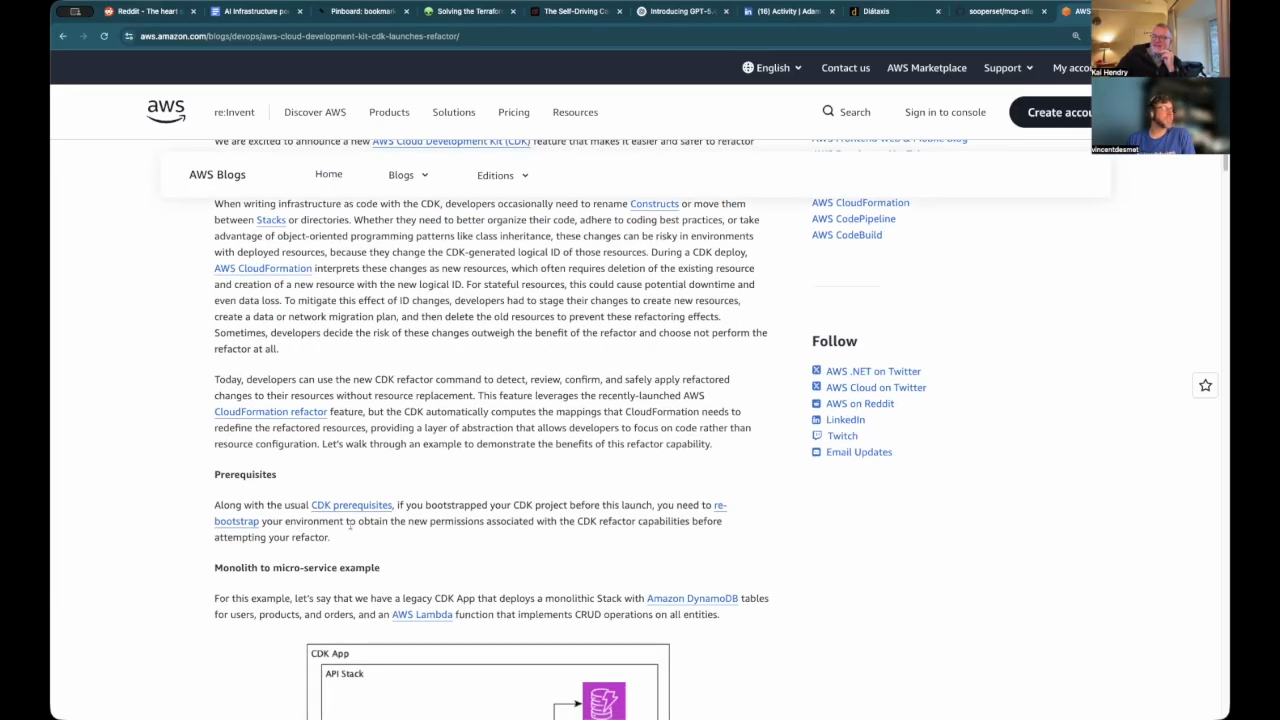
CDK vs Terraform refactor risks
When refactoring many duplicated AWS CDK apps into shared libraries they found logical IDs can change (causing unwanted deletes/recreates), so they compare CDK‑TF vs AWS CDK: both provide L1 constructs but AWS CDK has an advanced asset pipeline and bundling logic, whereas Terraform makes plan parsing and scripted move blocks easier—one host has a Python tool that parses a Terraform plan, maps one create to one delete, and emits move blocks with a top comment to review.
Assets, construct hub, and build pipeline tradeoffs
They close by describing AWS CDK’s asset/bundling features (automatic Lambda packaging, S3/ECR assets) and the construct hub/ETL pipeline that leverages step functions and Lambdas, mention tools like Progen for file-system constructs, and debate zip vs Docker artifacts and how security scanners can complicate packaging decisions before wrapping up the episode.
Model: openai/gpt-5-mini