Episode 36: Agent loops
Published: Wednesday, Jun 17, 2026 • Duration: 64 minutes • Season 1

Download MP3 | Watch on YouTube
Agent loops, release automation, dry-run simulations, multi-model harnesses, skills vs MCPs, and enterprise permissions for agentic workflows.
summarize "https://youtu.be/bi1FOTAZBkY" --timestamps --slides
This is a wide-ranging conversation about building, running and governing AI agents for developer workflows: live anecdotes about agent wins and failures, how agents can run deterministic tooling versus exploratory simulations, security and CI/CD implications, choices between skills and managed connectors, observability for agent runs, and practical governance (permissions, logs, Terraform). The hosts trade practical examples and operational lessons for teams adopting agentic tooling.

Opening stories and coding wins
They start with personal anecdotes: a favorite model got removed, a quick one-shot Swift tool was authored via an agent, and a “ponytail” style prompt was discussed (encouraging minimal, pragmatic code). The hosts describe using a review agent to scan PRs and run simulations, and warn against agents that just re-run CI without adding value.
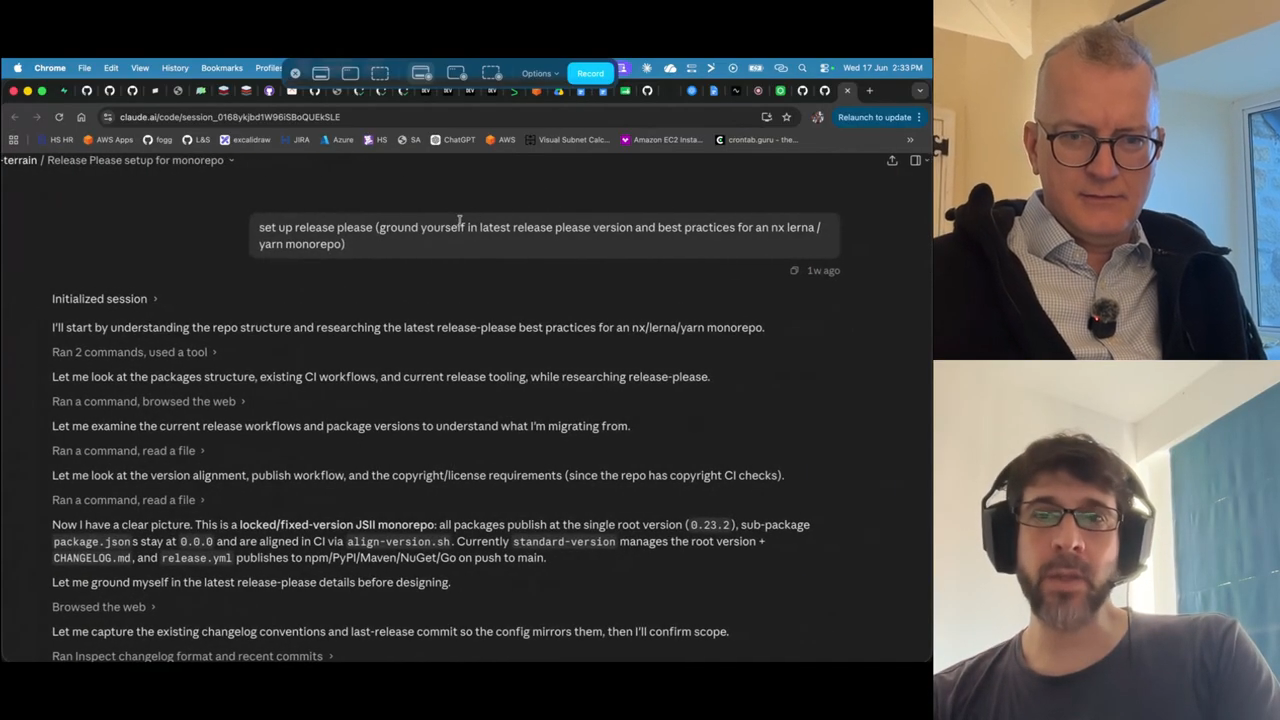
Release automation vs agents
They compare existing release automation (a standing release PR workflow that batches changelog entries) with delegating work to agents. Decision rule: use deterministic, battle-tested tools where available; use agents to reduce toil where no tool exists. Example: agent ran a workflow scanner to pin mutable GitHub action checksums and produced a deterministic patch for review.
Simulations and dry-runs as exploratory testing
A key agent capability shown is merging a PR into main in a temporary workspace and running a dry-run (release simulation) to surface issues that static review misses: title and commit-format mismatches, surprising changelog outputs, and other regressions. This is framed as exploratory testing — letting an agent do the human-y checks you’d otherwise have to perform locally. AI agents are creating massive PRs.
Multi-model harnesses, quotas and fallbacks
Practical details on API endpoints and budgets: agents often use different LLM endpoints for primary reasoning and auxiliary tasks (summaries, embeddings). Hosts describe quota exhaustion, automatic fallbacks to other models, and the trade-offs of trusting hosted harnesses versus building your own agent stack. Network and session stability (hotspots, sandbox limits) also shaped the UX.
Skills vs managed connectors (MCPs) and knowledge work
Discussion of when to build a skill versus using a managed connector: MCPs excel at auth, secret management and live integrations (Drive, Jira, Docs) while skills can be lightweight but often stagnate. For private documentation, semantic search plus embeddings is powerful but has maintenance costs (indexing, staleness). Good KBs need feedback loops (upvotes, flags, usage metrics) — that’s where products like CQ-style systems differentiate.
Permissions, identity, and human-in-the-loop dynamics
Enterprise control: map agent identities to allowed tools and data, allow-list agents and MCPs per user/team, and avoid agents running under broad human credentials. Auto-mode reduces friction but requires trust and careful stop/interrupt UX; logs and replayability are essential for rebuilding trust when agents misbehave. you engineer the loop, not the prompt.
Observability, audit trails and governance
Operational lessons: capture agent session logs, gateway events and tool calls so you can debug misconfigurations, run retrospective “dream” workflows to find failures, and surface issues via dashboards. Avoid unmanaged click-ops; when LLMs change infra, require a Git-backed plan and review so changes are auditable. The hosts push for platform tooling (Terraform, controlled admin panels, scoped tokens) to prevent hidden drift and speed incident resolution.
Model: openai/gpt-5-mini