Episode 27: Distracted by AI
Published: Tuesday, Apr 7, 2026 • Duration: 70 minutes • Season 1

Download MP3 | Watch on YouTube
Show notes: https://docs.google.com/document/d/1zoc-0L1o1Cyxtgatb9fN_ZGBGbshZIb9BTzwEj0C4Gc/edit?usp=sharing
summarize "https://youtu.be/oyGi8ahf4Og" --timestamps --slides
This episode (27) is a long, wide-ranging conversation between two engineers about practical pain points as AI tools get folded into docs, development workflows and platform ops. Main threads: converting Confluence to Markdown then letting AI rewrite huge doc sets (500 pages) created disagreement over the source of truth; agents vs persistent docs and the idea of ephemeral AI views; tools and patterns for agent orchestration and spec-driven development; platform-operational stories (data teams, Airflow on Kubernetes, Terraform tooling and testing); and an extended discussion of software supply-chain hardening (OIDC publishing, gating packages by age, CI security checks). The hosts trade concrete examples, versions and configs (for example a 4‑day / 5760‑minute package-age gate) and surface practical tradeoffs rather than evangelism. we couldn’t decide what the source of truth was this world is probably going to look pretty different in 2026

Converting docs exposed a new governance problem
They moved 500 pages from Confluence into Markdown to make docs agent-readable, then used AI to rewrite whole swathes; the rewrite quality was good but the team couldn’t sign off because the scale (hundreds of files) made review infeasible, so the project lost consensus about the canonical source. The hosts stress a core rule: keep a single source of truth and avoid many persistent derivative views; when AI generates fixes you must break changes into reviewable, small PRs and distribute review work so humans can approve incrementally.

Agents for discovery, but humans still uneasy
Making docs queryable by agents seemed like the intended flow—ask an agent for ephemeral answers rather than maintain many rewritten views—but not everyone is comfortable trusting ephemeral agent outputs because of hallucination risk and review norms. The concrete governance suggestions: keep core docs authoritative; use agents to discover and create ephemeral views; if a derivative view must persist, make it a reviewed, human‑signed artifact; and break AI edits into small, reviewable commits so the whole team can approve changes.
Agent tooling and spec‑driven development are exploding
They compare frameworks that keep agents running until tasks complete (spec‑driven kits) versus interactive, chat‑until‑done styles. One tool keeps an agent looping until spec completion, another uses adversarial agents (spawn reviewers that challenge outputs). Early adopters can move faster—one friend reached advanced agent orchestration in a week or two—while long‑time users risk being stuck in legacy habits. A concrete example: a junior engineer used an AI tool to find a memory leak in ~5 minutes where a seasoned engineer would have gone through traditional heat‑map workflows.

Platform work: data teams, Airflow and production friction
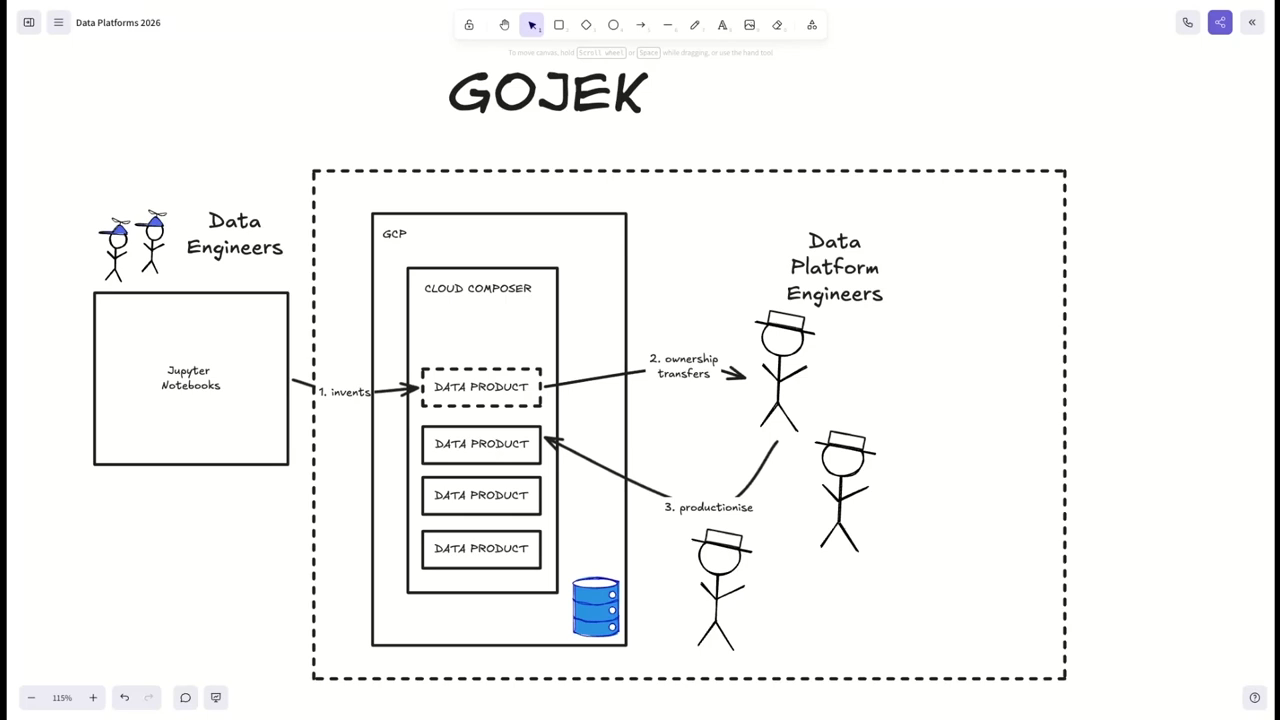
A former data‑platform engineer describes handoffs where data engineers prototype in notebooks and platform engineers productionize poorly tested work thrown over the wall, creating heavy support load and stress. Airflow is discussed as a tricky shared infra piece: earlier patterns mounted huge DAG volumes and ran monolithic runners; by 2020 native Kubernetes job runners and per‑job secrets injection made deployments far smoother. The upshot: platforms must become much easier—possibly “AI‑easy”—because expecting product teams to read docs, create repos and run workflows is a big barrier.
Infra tooling tradeoffs: Terraform, CDK, testing and local emulators
They debate Terraform’s limits (no automatic rollback, heavy module complexity) versus CDK’s higher‑level abstractions and shift‑left benefits. Testing stacks: use Terraform’s built‑in test command for fast in‑memory checks, and use teratest when you must provision and assert runtime contracts (AMI builds, network or NAT instance permutations). Local emulators (localstack alternatives) are useful for quick serverless work and take‑home coding tests, but licensing and CI restrictions can change the calculus. The hosts also discuss porting CDK L2 coverage to non‑native backends so you can use higher‑level patterns without the original service runtime.

Supply‑chain hardening: OIDC, package age, CI gates and noisy scanners
Recent supply‑chain compromises drove practical mitigations: publish with OIDC short‑lived credentials to avoid long‑lived publisher keys, and gate dependency updates by age (example: require a package to be on the registry for 4 days = 5760 minutes before accepting it) so immediately pushed malicious patches get a window for detection and takedown. Also, gate automerge with CI security scans (npm audit or equivalent) rather than relying on unit tests alone. They warn about noisy scanners and config overload but point to concrete CI rules: run an audit-level scan and only auto‑merge when security jobs pass, use minimum‑release‑age tooling in dependency bots, and prefer package managers with good audit support; one practical config discussed was setting a minimum release age flag to four days and running an audit step before auto‑merge.
Model: openai/gpt-5-mini
Transcript (auto-generated from YouTube captions)
Well, this is episode 27 of the AI infrastructure podcast. This is an intro coming from Cornwall, a windy one. And today I'm driving to London, to the big city for the AI engineer conference. So, if you're there Wednesday, Thursday, Friday in London, do say hello. Otherwise, I will be uh reporting back from that event. I'm sure it will be very interesting to meet lots of AI enthusiasts. And um enjoy the pod. I think it was a bit of a weird one where I was talking about the documentation problem again that AI presents. And uh we were just rambling about other things. So, hopefully enjoy it. Um if you didn't, comment below. If you did, like it and comment below. Otherwise, please enjoy the pod. Good morning, Vincent. Good morning. And it's Good Friday. That's nice. I didn't >> You're on holi- You're on holiday? No. No, I have to do some work. But it's okay, I have to catch up on some work. It's pretty interesting work, actually. Okay. So, I I'm just editing the uh doc that we share. I was adding some uh things to talk about. Oh, let me just I guess this will be edited out. Uh so, perhaps I I could we could start with a quick fire questions for you. I'm going to probe the depths of your mind. Yeah. Um okay, the the the first couple of bits are related to work and which I might have uh delete, but uh whatever. Uh sorry, um Claude Code is blocked. I need to be unblocked as soon as possible. Sorry. Cloud com- Claude Code comes first. >> Just it asked me something. For local compose test, so we should keep the test for a secret command being available, I believe. Okay. Um yeah, sorry. Go ahead. We talked about docs uh last pod and you recommended keeping documentation in the source code. And you showcased some pretty cool abilities. I just wanted to say that like at work, we did manage to convert all our Confluence to markdown, which was great. But then, once it was in markdown, uh it was too tempting to to to to use AI to basically improve the docs. And then, of course, Uh pardon? And last time you mentioned that Yeah, and then people created different copies with different type of angles, right? And Yeah, I wouldn't say co- We didn't go down the route of copies, but we got we got into almost a worse situation in a way. Perhaps it is the same as copies, but but since it was rewritten, we couldn't decide what the source of truth was because people were were saying like, "Well, no one's actually gone through all these 500 uh files of rewritten documentation. So, we can't like sign it off cuz it's just too big of of a rewrite. Essentially, we couldn't decide we couldn't like we couldn't call it a a success because because so, I guess it maybe is a is a story to to to say around AI where maybe we should just go slower or something like that just to get the buy-in. But at the same time, it's just so easy to to tell AI uh rewrite all the docs in different ways. And it works for one person, but it doesn't work for a team is what I was trying to say. Well, okay. Maybe you don't have anything to say to that, but I just wanted to Why didn't it work for for for a team? Because the team the the Confluence or the documentation that we have was was pretty extensive. There's like 500 pages. Yeah. And no one was going to Most of the team were were not prepared to like go through the documentation and and basically, you know, approve it. They just did they felt uneasy. Approve it because the changes were too too much like it needed additional review and approval of like the changes that were introduced. Yeah, but when you're in a big team like effectively, the whole team had to get behind the documentation cuz the documentation sort of describes how to use the platform, how to do this and that and the other across all different sort of aspects across a very large landscape. So, so basically, it wasn't because one person needed to make a decision. It it was like the whole team really needed to get behind the rewrite and it was just impossible. >> Okay. No, because like there's this couple of interesting sharings that I read just today one and then there's another one that um I don't forgot forget the context. Um but you mentioned something about if you create like docs all over your repo in markdown, they become maybe harder to discover than Confluence if you just use Git as a as a as a storage mechanism, which is something I always say, right? You should have your docs in Git. But also, people are saying you need to have your docs available to the agent because ultimately, the agents are going through these faster than humans. >> Yeah, I mean, step one was that we we did manage to get our docs into markdown um available to the agent. But then, that that was that was all done, you know, that was done. But the second step is like the um the the generated docs, we we just couldn't agree on it cuz cuz like what um Okay. Let let me just flesh this out. You know, like one way is that you could you could like if you want uh to find info, you could you could always ask uh the the AI agent. Right. So, the core source of truth should always remain, right? There should not be like derivative docs. >> Yeah, but the trouble the trouble is the docs they are quite expen- they're quite extensive. There's 500 pages and there are actually like mistakes in them. But okay, that aside, the trouble with that approach is that like um not everyone is prepared uh is is is prepared to to read docs that way. Okay, so what you're saying is you moved them out of Confluence into markdown, so they became available to agents. You then had one approach of asking agents to generate different derivative docs, but that's not good. We discussed it and you said we should keep a single source of core docs. And then you discover docs by asking agent. You find the information by asking agent, but not everyone agreed to that. Yeah. And then with with the core docs, the you know, huge temptation to let AI, you know, fix things. And then um which you did actually in and I I think it did a sterling job. I couldn't actually find any major issues. But then then the issue is that not not everyone in the team wanted to approve it. wanted to approve it because it basically uh since it touches like 500 files. Yeah, but >> That that sounds like Okay, because when you said that earlier, it felt to me if you're moving out of Confluence and you're moving it under version control, the migration should be a one-to-one. There can be no argument about this is not the same. It's exactly the same. And then you need to decouple. And if you say we're going to let AI fix things, and if if there is this hard requirement within the organization that any change to these docs now needs to be approved, um you have to be um and reviewed, you have to break it down in in in reviewable chunks, right? So, if you let the agent makes the fixes, then you have to ensure that the fixes remain um you know, small PRs that are reviewable so that you can get buy-in and maybe distribute the review work across different people uh in a way. I I I'm just thinking. I mean, I constantly have this problem with AI that I keep blowing up the scope and pulling in more changes. And it's very hard to just say no. I mean, if you're talking about code, we've come to the conclusion that a lot of people say we don't look at the code, right? Even um Adam Jacob's talk at the config man configuration camp Yeah. Yeah, I can't believe you just watched that one. I I'm sure I shared it with you 3 months ago. >> went an hour When I watched it, it was an hour on YouTube. So, Yeah, I I included a timestamp. No, it was an hour ago posted on YouTube when I watched it. Was it on YouTube? Yeah, it was. I don't know. I didn't because when I watched it yesterday, I can I should go check. I thought it was not on YouTube before. Anyway, it doesn't matter when or what I watched it. Yeah, I Adam Adam's I love his talks. Well, it's a very good opening talk uh to to ex- to um convince people, to give people a summary of where the world's been headed. And it sounds like he's basically spending 35 minutes convincing the room that yes, AI is coming. Yes, it's bigger than you think. And yes, it's changing everything and the way you think. But here are the things that I learned the last 3 months using it. And and it's great for that. But even though it was recorded in January, so when you watch it today, it's already outdated. Um he draws >> How? he draws the boxes of what has completely been dominated by AI agent. And he shows like the human is in in response for design. The human is responsible for plan. And then the agents are is responsible for implementation, validate, testing, and deployment, or whatever. I don't remember the exact boxes, right? And I just thought when I saw those boxes that I haven't really me personally reviewed a plan generated by an agent. I just ask another agent like adversarial review agent. So, you just give another agent complete blank context. That that do the cross reference. And I posted it as a comment and he agreed with me. He said like, "Yeah, that's already a case for for for his experience as well. They are not reviewing the plans anymore. They're doing adversarial agent reviews." And so now we are just part of the design. Yeah, adver- sorry. Adversarial, sorry. Adversarial, I keep saying it wrong. >> Adversarial What's the the whole phrase, sorry? Adversarial agents or agent reviews. Here they talk about networks, but it's it's definitely a a hot keyword right now in in the AI bubble. Yeah, I'm not I'm not 100% sure I can get agree and get behind this yet because I haven't managed to uh Like for example, I don't know if you shared it with me um or I shared it with you or I just found it by myself. um Oh, there's this thing called cook and it it essentially makes it easy to um I can't find it now. It makes it easy to to do this adversarial thing in the sense that like spawn an agent that reviews the other agent. And I used it and I thought to myself that I wasn't convinced because it it made the solution more complicated if anything. It It just It just It didn't get to the to the to the solution that I wanted, but that was just one anecdotal data point, right? So, anyway, we were talking about adversarial agents, why? Because things are outdated, but okay, you're talking about Adam Jackson's talk. Yeah, I was also just wondering a minute ago how did we get there, but because you were talking about docs and breaking down chunks into smaller reviews and I was saying that that's one of the biggest issues I have with scoping down the amount of work that the agent submits because because I then trailed off in the thought that we all agree that we're no longer reviewing the the implemented like the code, but we we now supposedly only review the plans generated by the agent and I'm just saying we don't even review that anymore. Um so so basically, I think we got there because we were talking about what needs to be reviewed by humans, right? So, so if you need to produce something with AI that needs to be reviewed by humans, you have to resist the temptation to let it become a massive amount so that they will have a you know, rejection because it's too much. They have no time to review it. Basically, that's the point I was making. >> Yeah, and and to me that's like a trap. And to be honest, I think we even went down that way at work for this documentation. And we were just saying like, "Hey, we got this view. We got this view. We got this view." You don't need to It's It's too much to >> Why are you talking about this view and this view? Are you creating from the same core docs different views? Because we already agreed don't do that. Okay, well, I'm just I'm using it as a as a as a terrible example of like like I got to a stage where you where where where we wanted to say don't review and then and then then we have a right mess, basically. Okay, so it sounds like because this is discussion we had last time and I'm not sure if we still want to go deep into this topic right now, but we agreed that at the time that there are a certain source truth core documents that are the single source of truth and then you said we we said we should use agents to query the docs and find and just basically create like ephemeral views that that gets caught thrown away and then you said some people are not confident because I can I can I can see that, you know, why would you not assume the agent is hallucinating in one of those ephemeral views, right? Unless you generate a more like persistent view that is actually reviewed by a human to confirm that it is not any hallucination in there. And then you would start creating um other views that are persistent, but it's not good. So, it's really um Okay, make conundrum. Yeah, it is quite a conundrum. uh And yes, the talk was posted on YouTube a month ago. I just checked. So, my mistake, not an hour. And here's the what I was trying to talk about earlier. Here's this CLI that I was using. So, when when you first set it up, you basically say which which which models you want to use like Claude and Codex. I mean, all you know, OpenAI and Claude. And then and then you ask it something and then it has these little like uh tags or I don't know what you call these little arguments where you can basically instruct the three parts other agent how to review the code or or you know, go three times or how to what what the evaluator function is or something. I and I used it and it works beautifully. But my friend's observation was a lot of all of a lot of these frameworks and he he started using get done, GSD. And he says it's very funny because it's literally just a whole bunch of markdown prompting and thin little layer of JavaScript. Yeah, and and a little loop you know, like >> And a lot of the these things are like that. Yeah, exactly. Exactly. I mean, And he says like, "What are we doing? Like what's the value add here?" >> yeah, and mine I mean, I love it in the sense that like it's beautiful to see these agents working in in concert. >> Mhm. But the results were not good, but maybe I need to give it a a better try. And another you know, feedback I I got because um my friend has been mostly using cursor or a little bit of agentic in cursor and he's been happy with it. And I've been asking him like, "Hey, you know, I'll use spec ledger with you and then you'll get to experience what is spec driven development and I will deliver some feature that whatever you want gets implemented." I told him. And he he wanted to drive, so I said, "If you want to drive, then you should have." And he says, "But I want to use chat GPT models. I'm not going to pay for Anthropic. I have already chat GPT." And I said, "Okay, then you should use open code." "Why not Codex?" He says, "I am not I don't support Codex CLI. I only support open code because it's more similar to Anthropic Claude Code in terms of they are trying to match the tool usage and stuff in the agent realm. >> Okay, okay. So so he then decided, "Okay, forget it. I'll just use cloud code then." And he's been using cloud code for a week now with spec driven development and he I think maybe he might have used another one, but he was frustrated, so he started using get done. And he said like within 1 week 2 weeks, he was like, "This is amazing. Like why didn't I do that before?" And then he's he's already like running agent he's using get work trees and sub agents. And he also subscribed to the Claude Code next plan and um So, he's been red pilled. Like and he's asking me now how do you use like sub agents and work trees and agent teams and review agents and I'm like, "I'm not there." >> [laughter] >> I'm like heads deep in just the spec driven development side of things. I haven't really like I I have on purpose avoided going into this whole agent team orchestration because I believe that there's so many people doing it that soon enough it will be like, you know, perfect and I just need to wait a little. Yeah, so get so get done is is like that cook I was just sharing, right? Is it like that? I mean, He says it's a spec driven development toolkit that that is more like proactively keeps the agent running until the things are completed. Cuz a lot of the like spec driven development frameworks, they aren't really like keeping the agents in loop until it's done. Uh and apparently get get done does that more. Like you see, I've done spec kit open spec, but get done is actually delivering the results. I find that a little bit difficult. I'm definitely a a Peter Steinberger kind of guy. I just chat with the with the AI until it's done. This one seems to I wouldn't refer to myself as Peter Steinberger if I don't run if I don't have five you know, open code accounts and I'm running you know, 20 terminals at the same time. I wouldn't do you know, because this guy is on another level. Yeah, he he's obviously very good at context switching. I mean, I I like to think I'm pretty good at context switching. Like I can I can you know, spin three plates, maybe not five or 10. Mhm. Um well, I don't know what to say to this, but I guess I just need to give it a try. But it doesn't seem quite the same as as though that cook thing, but maybe maybe it's worth looking. I mean, there's I mean, this is the crazy thing why we we need to talk every week because there's a bazillion projects, aren't there? Yeah, it's moving really fast and and also what I took away from my my friend's experience is that even if you haven't looked at this, it takes maybe a week or two and you can be at the front, you know, trying to use the latest of the latest. >> Yeah. And maybe it's a good thing because if you've been using it for 8 months, you're like stuck in your old behaviors and the models have moved on. And if you come in a fresh, you're like no idea where to start, but this is looks like what what people are doing, so I'm going to start doing this. element of beginner's luck. It's not like beginner Yeah, well, it's it's just being able to shed your your legacy or tribal knowledge and being able to cuz even Boris Chef Ni, he says that he's stuck in a lot of old ways when he's doing troubleshooting. He always gives this example where he says there was this memory leak and and he he has to avoid going into his habit of going going into an heat map to identify the memory leak and then somebody younger who joined the team and has really adopted Claude Code, you know, just went, "Hey, you know, I just asked Claude and within 5 minutes it found the memory leak. Whereas you started going into your heat map and you know, 20 minutes later you still nowhere and Cloud already fixed it. So it's it's really part of and then Boris says it, it's part of the models are so good. I constantly have to remind myself to like cut those old habits and just ask the model. Yeah. Speaking of Claude Code, I I think I don't know if this is real but I did see some comment that someone analyzed the the source code drop and there was some talk that there's a way more powerful model in the in the works but I guess that's always going to be true really. But like I don't have my faults or Metas. Yeah, when the new model drops how is it going to change things? I saw a screenshot on Reddit which could be completely fake but like the improvements compared to Opus were significant. I mean the way it was discovered when I I heard about it before the drop was because Anthropic apparently left information in a public database. It wasn't like a meta dot dot dot database. It left some information about this Metos project or Capybara or something like that. And and that's how I heard it was uh But it says quite a lot of like first of Anthropic like up time being such a horrible I heard a lot of people moved away from Anthropic because they are not able to deliver their reliability. Yeah. Yeah. They had a huge They had this huge issue with token caching so your usage would drop significantly like people would send one or two messages and they would hit their 5-hour budget because um there was a bug in the way that the two the cache was working and it was also happening when you restarted Cloud. So people were like finding the bugs and even when the short source code leaked people started to debug those bugs. There's a memory leak I'm going So not a memory leak. It was two significant bugs that the community highlighted and and that they had to fix. So they have been having a very hard time. Then all of this like internal information leaking about models being underway. So people are like right now on Reddit it's very annoying because every day there's three or four posts of people saying you know First of all weeks they complain about the the token usage budgets depleting too fast and now Anthropic has released .90 and .91 fixing some of these issues and now people are posting yeah that's not fixed until you refund you need to refund because we couldn't use it. You're all in on Anthropic right still with your max plan? I don't want to support Open AI. I like to think I'm being a bit balanced like I've been moving between Open AI and Anthropic. I still have ChatGPT. I canceled it they give me one month free but I haven't recanceled it. So you need to cancel it then they give you one month free then you if you Yeah, yeah. You need to cancel it for real after one month and I haven't canceled it because my wife really likes using ChatGPT. Mhm. The I think the voice mode is also Much better than Yeah. Um phone app. Okay, let's change topic ever so slightly. I wanted to ask you quickly if you've ever worked on a data platform. I worked for some engineering I mean I I think it's >> Enough time has passed and I can talk about my Gojek experience. Mhm. I I worked briefly at Gojek and uh it didn't work out to be honest at the end of the day. Not going to lie. But the but when I when I worked there uh as a data plat I was a data platform engineer. It was interesting um in the sense I I don't know if you've ever seen this sort of model like this. We we had data engineers and about 5 or 6 7 years ago data engineers was like like for some reason like really popular. I'm in fact I think you you still see it today like you do these like boot camps and then people learn how to become a data engineer. You know what I mean? Like it seems to be a role unto itself. Oh oh I can see you're distracted by the Claude Code. Now what what what would happen is that the the data engineers would get some data or get some task to to wield some data. They would jump in the then Jupiter notebooks and then they would come up with a POC about how the data is going to look or how it's going to be end up or something like this. And then and then that becomes a data product. But the trouble is is that they since the the these data engineers were kind of like fresh grads mostly or they were just not really uh I don't know what the reason was exactly. Well they they lack some skills to productionize it. So so they they would hand over their work essentially to data platform engineers and then we would productionize it. Have you ever seen something like this before Vincent? I mean I've never really worked inside of data team. I have supported a data team as a platform team um for one of the data teams I worked with I was managing their Airflow deployments and also helping them define how they would get secrets to the jobs in Airflow and also That's typical. It has secrets to I mean since since Airflow is like a shared thing I the Cloud Composer I think is is basically Airflow. All right. Yeah, essentially Airflow is quite an infrastructure challenge because it's I think it's got some horrible assumptions that everything is run on a shared instance and then of course when you have lots of data products. Uh I was running So at Honestbee back in 2016 they were using Airflow and the or they adopted Airflow at least around 2017 and they hired someone an ex-DevOps engineer who wanted to go into data and he joined the data team and they only give him one job which was to deploy Airflow. So he was pretty pissed. But but he was used to run Mesosphere. So he was running they I was running Kubernetes for the the the product which were like several big Ruby on Rails applications and they approached the the platform team for uh you some type of job running framework and at the time 2017 the job API like the resources of for running jobs in Kubernetes were like alpha or beta they were very unstable. So I said yeah we can do jobs but and so they decided okay I'm just going to go with what I know and rather than to talk to us they just deployed Mesosphere. I was like what you know why you deploying a competing like another container orchestration system. Anyway they ended up with having this huge Mesosphere cluster that was mounting the file system. >> to Airflow right to jobs? Yeah because of Airflow. They was just because they didn't run anything because they were using That's that's a typical problem like everyone is on the shared Airflow instance and then they go like oh we have secrets we have things data we need to containerize it and then they come up with some hodgepodge containerization solution. >> because I managed Airflow at another company like four years later and it was completely different. None of that what we just mentioned. In Honestbee we had what the problem that you just mentioned. They had they basically containerized Airflow by creating a massive image and then mounting a file system into it with all of the DAGs. So the whole all of the DAGs was just one massive volume. So the image was just something like a shell Yeah. I don't think that's that's a that's a good idea. That's like containerizing Kubernetes. And the only reason I know is because and everything. The Yeah yeah they they basically run Airflow which I also thought like why do you need to run a job runner on top of a job runner? Like why do you need Mesosphere to run Airflow? Okay, okay. Okay. So when I inherited it but then I can tell you one thing okay doesn't have to be that way with Airflow because I deployed Airflow in 2020 which was like four years later and and at that time Airflow had a native Kubernetes job runner and it has a native Kubernetes orchestrator. Cuz originally Airflow was like using Redis to distribute jobs to runners but with with with the Kubernetes integration it was using Kubernetes as a job runner interface and it would talk to the Kubernetes API to spin up a pod which was like an Airflow worker node and then you it would get the the DAGs from I think we put them on S3. Yeah I don't remember how we delivered the DAGs. But it was definitely not like a huge massive like file system. So then actually it was really manageable. It was really very smooth and the secrets was easy because we were using like um secrets directly for jobs and they were just getting injected when they needed it. Not shared nothing like that. And that was in 2020 so Okay. So so sorry I I I was a little bit distracted. So how did what was the solution ended ended up being again? Airflow supports Kubernetes as a as a job Really? All right okay that's interesting. It has for a long time. I actually need to investigate that. We were just like back then we're using the the managed GCP version and then recently I've been running the AWS managed version called managed workflow I don't know MWAA. But it it's Okay, that's something to look up. I mean what what I wanted to sort of perhaps tell you was perhaps um not nothing AI related it's more to do with organization. I mean as much as I didn't I actually didn't really like this model at all because the data in there was so there was a lot of data engineers and and the data platform engineers which I was a part of we were really like overloaded with work because unfortunately we needed to know what they were doing because sometimes they would just throw over the wall um some some code that just basically didn't even work and we would have to like fix it and own it from end to end. So we were like basically working on new products all the time and as well as supporting old products. It was quite stressful. Yeah. But nowadays I think I think back to those five years ago and I think to myself like a lot of the work that we were doing wasn't so like inventive. You know what I mean? Like we we didn't come up with the the products themselves. They That was kind of part of the day data engineers things. But we were part of like productionizing it. And now with AI, productionizing probably becomes easier? Debatable. I mean, I don't think AI's super proven to ship, that isn't it? And productionizing is about shipping. But I still I still maintain that this world is probably going to look pretty different in 2026. That's for sure. Um And then And then also I just wanted to contrast that with what I saw what I saw kind of recently on a on a gig where basically um Yeah, basically people are expected to to know a lot more to do the job. Like it we created, you know, a proper platform where they where they had you know, had to create a Git repo and all that sort of stuff. And to be honest, I I think it was just too difficult for for for people to do it that way. I don't know if you've ever created a a platform where you know, there's a config YAML and you know, product teams are are expected to to deploy their own app. I I think to I think to myself that that's just too hard. It's too hard. You They've got to like It's got to be a lot easier for different in a big enterprise. It's got to become really really like AI easy for people to create software or a solution for for their particular problem. Can't expect people to like read docs, set up GitHub repos, run workflows. It's just too hard. That's That's all I wanted to share. I definitely have problems where the platforms I create around Terraform are for some people too um let's say niche. Yeah, yeah. That's a typical one cuz like like we find Terraform easy. But I know I know like as soon as you you tell a data um a product team like, "Oh, you have to deploy Terraform." Then mind just explodes. Yeah, but the problem with Terraform is that it's not a very good product. Like it has the Go lang mentality of it's better to rewrite something or duplicate it than to create coupling, right? Um what we are doing often with Terraform is we are creating abstractions that then create coupling between different parts because we're trying to reduce the the boilerplate and the repetitive repetitive repetition. So this is kind of like where it starts to then become complicated for people because we create these meta layers around Terraform. Mhm. So Terraform in itself can be bad. And modules Modules in Terraform also just flummox people then they like don't know what's going on inside them. Terragrunt reached V1, by the way. What? Thinking about layers that complicate Terraform, Terragrunt was released with an official V1 like stable thing. >> But Terragrunt has been around for a long time. Yeah, but they never did a stable release. So they finally released Terragrunt V1 and they included stacks, um which But they've been working on stacks. Well, I used But this isn't exa- exactly an example of where Terraform is meant to be simple and then it becomes too unmanageable because of the amount of config files and repetition that you get. And then people build layers around it like Terragrunt and it's a prime example of creating complete like super hard things to understand because of the complexity it it allows you to do. I don't know, they probably improved a lot of it, um but I used Terragrunt in in one organization which was rather large. And I feel it was very successful in the way that it managed our infrastructure as code, but I also feel it was a massive blocker for anyone that wasn't platform to then contribute to that infrastructure as code. Yeah, I guess that's a good example. And the same with Terra mate and all the others. Anything that's a Go lang CLI around Terraform is like that. Yeah. And do you think I mean, compared to CDK? Uh good. Um because CDK gets rid of the Terraform modules, which to me I think is the biggest problem. Most of these orchestration system try to work with Terraform modules. But Terraform CDK or AWS CDK completely gets rid of it by creating a higher level abstraction because it has it is not just like a scripting library, something that can do simple loops or things like that. It's an actual complete programming language language and it allows you to create object-oriented things such as extending an a base class, implementing interfaces, it's allowing you to do dependency injection by just making sure that the constructor takes in the something that implements the interface. So you get a lot more capabilities than what you can do with Terraform modules. So we're there CDK is not stuck in this like I just have to script around the whole bunch of stupid Terraform >> converted. I'm converted. We talked about this. We talked I think one Terragrunt was comes in view because of TerraTest. Do you have you ever used TerraTest? I am a heavy user of TerraTest. Really? Yeah. I just today was walking through We're having AMIs built. So I used TerraTest mainly for I think TerraTest is amazing. If you have home-cooked AMIs that come with a pairing paired module. Like for example, you know that there's this thing called FCK net, which is like a feasible cost um net gate like net instance. So instead of running Let me Google this. FCK what? >> net NAT, network address translation. It's like a 10% cost of an AWS NAT gateways. >> Oh, so it's just like a a NAT gateway replacement. >> AWS VPCs support NAT instances. So you can set up your routing tables to route all the traffic through one EC2 instance. You don't need a NAT gateway. Mhm. So basically I I forked this AMI because it's literally like a 50-line bash script delivered through a systemd one-shot to set up your IP routing tables and um I'm sure people are not doing that. It's just IP tables and it's just registering your ethernet interface to act as a egress interface, right? >> Okay. So it's very very basic small little thing and it's amazing. Um and I have a it together with a module. I have a Terraform module that basically deploys this in several configurations. It can be a single NAT instance in one subnet and then all the other subnets routing tables are routed towards that NAT instance and then you would do cross AZ that way. Or it can be one NAT instance per subnet. So the module has many configurations and they need to be tested because it's a contract that you support. TerraTest is amazing. Yeah. Um so so what >> I I I was just trying to remember. So TerraTest is basically te- is testing your your what do you call it? Your deployed infrastructure, right? So what TerraTest is is nothing but a bunch of Go lang modules. And what it shines through is the Go lang testing capabilities. Go test? Yes, Go test because Go test can run test in parallel, it can, you know, do all kinds of like subnets tests, table-driven tests, and you can defer so clean up functions can be deferred. So Terra- TerraTest is just leveraging Go lang test framework and it's just a a whole bunch of like AWS SDK API implementations so that you can you know, um on one side it it does OS exec Terraform, OS exec Packer to test your Terraform module and your Packer build script. And on the other side it has a whole bunch of assertions that you can do. Is the instance registered with SSM >> in the past, but like I mean, the landscape I'm using it. So since Terraform has added Actually, I have a presentation about this that I delivered in a conference in in Singapore. I think there's different layers of testing that you can do with Terraform. And the first one you should use is the built-in test command, right? Mhm. Because the built-in test command is pure in memory. So compared to TerraTest, TerraTest is going to provision everything inside a file system and it's then going to run Terraform in it and it's going to take a while. Whereas if you use the Terraform test command, it's going to create everything in time. It's you used the Terraform test command? It spins resources up. >> Yeah. So I use both. So I I used the Terraform tests files in my module for some basic cross variable validation like does a variable condition is it triggered as expected? For example, I have a module and you should set one variable and not the other. And if you set both, you should get an error. So I have a test around that. So do you So you use TerraTest with your CDK your Terraform CDK stuff? With my my library that I built, basically porting the AWS CDK L2s, I used TerraTest to validate that the L2s work actually deploying. Yeah. Really cool. You should mention that on your CDK trends. It is. Uh not on CDK terrain, it's on TerraConstructs. Okay, okay. Which is the L2 porting on top of CDK terrain. But there's some really exciting like things in the work around that. So soon TerraConstructs will will be no longer needed, hopefully, and we can have something directly that is going to have all of the coverage of AWS CDK. And that's going to be amazing cuz then you can use it with AWS CDK with OpenTofu directly. No more CloudFormation. Okay. Can you imagine that? That you can use all of those AWS CDK L2s directly with OpenTofu. That's it's going to be amazing. Okay. Let's That sounds interesting, but that's that's upcoming, right? That's upcoming. Well, I think it's it's it's actually more realistic now to talk about it because if you if you're aware, there's this one guy Kanto. I think he's a Japan based. He's a heavy contributor to AWS CDK and he like writes a lot of blog articles about how AWS CDK works and some of the features within and he's contributing a lot of really really big features. And he just announced something called AWS CDK direct. And what he does is he lets you run AWS CDK without CloudFormation. So it reads the CloudFormation YAML file and then issues AWS CLI commands. Like it just calls Oh, I see. I see. Something like that. Yeah, and he uses a state file as well. I might be a CloudFormation apologist here, but like CloudFormation kind of works. I mean, do you really want to replace it? CloudFormation? I mean, they made a lot of improvements allowing you to refactor and I think we're in a broken record, but it's it's pretty painful when you have to deal with logical ideas. Well, maybe that's no longer a problem because now you can tell CloudFormation that some resource has changed its identity, so it's not really need to be deleted. But one of the biggest issues is a crash loopback. Not Oh, yeah. The update crash fallback. Rollback. Yeah, that's been broken. But how does how does Terraform Sorry, how does Terraform doesn't have that. Just because of the planning stage will catch that or something. No, just because Terraform cannot rollback. You cannot rollback Terraform. Well, you you can disable the rollback uh you know, you can pass an argument to CloudFormation so it doesn't rollback. >> Maybe that's new. Not last time I used it, which was like 2 years ago, I think. Okay. Well, if if there is something coming out, I guess it's worth evaluating. Like I think someone asked me the other day like so with CDK you get more linting, you you get more shift left, right? I mean, we can we can because well, I guess you have the best you have the best of both worlds, don't you? I mean, when I talk with Adam Jacobs and I told him I don't know. I told him about because he's he's basically saying we don't have to live with legacy of Terraform providers. We can just rewrite the Terraform providers on demand with AI whenever we need it with whatever we need it. >> As someone as someone who's developed a Terraform provider, it's not easy. No, but and I told him like why would you need to do that? Like you're throwing away the baby with the bathwater. And he says, "No, the model is completely wrong. We need to get rid of it." So I was like, "Okay." I just said I don't understand that reply. So maybe you I'm not going to go further there. Okay. Um hold on. I want you to get on the topic whereby Sorry. What ecosystem gives you the max sort of shift left ability? Like one thing I noticed Let me just share this. How do I share my Like there's been a few local stacks sort of replacement >> Today there was like this mini stack. Yeah, there's there's been a few. I just noticed them popping up here, there, and everywhere. Yeah, since LocalStack is like changing their pricing model. >> called Flocky. Oh, yeah. I've seen that one. Um and then I noticed this this AWS developer I follow and I noticed I think randomly on GitHub. Sometimes GitHub can just show you what people are working on. And um hold on. What is my username? And I noticed he was working on this thing called um yeah, this Eman Fatih. Um he he This I mean, this this comes in my opinion, since he works at AWS, this comes out of AWS. >> No. No. No. No. You cannot. I can I mean, can you imagine working at a big old company then everything you does gets associated with it? That would be so annoying. I would hate that. >> Obviously he vibed it. I mean, you can tell. I was about to say and I like that there's Gherkin in it. That's super interesting. I want to have a look at that. Yeah, so um Okay, let me get my thoughts together. So you you use you use CDK, use Terraform. Okay, what is the best ecosystem that gives you the fastest iterations and before you even deploy on the cloud, that gives you the max amount of, you know, verification that what you built works. So to me it's it's something like using uh I guess in the past, since I don't have that much CDK experience except my last gig, I would use Terraform and I've maybe used uh LocalStack and and then I would just, you know, iterate from there and then I would deploy. That would probably be the fastest shift left way. But have you come across any faster ways of doing it? And I I don't know exactly what happened to LocalStack. Did they just go really pricey or something? No, they changed the license for um Before you could download the Docker images of the community edition and you could just run them, but now they removed those. They deprecated those Docker images and they only support the enterprise Docker images and you have to give it a token. So they are tracking your usage. And another thing that they did is if it detects that it's running inside GitHub Actions or in CI, it just shuts down. So you can use it locally, but you can't use it in CI at all. So that's where I think people got upset. One, you can't use it anymore without creating an account and giving it a token so that they can track you. Two, you can't run it at all in CI anymore. Okay, that's a good summary. Yeah. Um that sucks. So what in your opinion is the fastest shift left way of of doing it? I mean, I've always been intrigued by LocalStack and I actually like to use it for like take-home assignments because it doesn't require a candidate to have any account and I give them like a very basic AWS infra that allows them to um you know, do everything within the challenge that um that doesn't require that works without a LocalStack license or anything like that, right? But I have never used it for anything like um you know, [snorts] validating a large serverless setup. I think LocalStack only makes sense if you are really heavily depending on like serverless services, right? That you cannot Like otherwise you would just spin up like a compose environment or you would spin up a you know, the services >> Well, it's also good for all the like AWS native, you know, Kinesis and So I I have I built like this the Terraform provider that uses SQS and I wanted to validate it really fast and you can you can actually have like complete emulators of of SQS. I'm not sure about Kinesis, but I'm I would be surprised if you don't have that. And the funny thing is those are like dedicated projects, which I think are better than going with like a massive library that tries to track everything. Yeah. Yeah. Yeah. I know what you mean. Like there's a few like DynamoDB type Yeah, and and and the the one that I was using for SQS was um Was it ask Yeah, it was SQS. Was the was written in I think Elixir or or um something like Java. It actually Yeah, I think it was using the JVM under the hood. Uh is it Scala? It was something crazy. Like I would never use it. I was like, "Ah, I can't use that because I don't I don't understand." >> self-contained as well. Yeah, it was absolutely like yeah, it didn't didn't matter what it was written in. >> of most of AWS is probably some insane Java. Yeah, but I mean, this was a this was like a a public thing that just um exposes the same API endpoints. And I had good success with it. I was very happy. Like at least I was able to test this one little thing that needed that one little service. So I could run it locally. Um but that's why I never use something like LocalStack uh except for like candidate take-home assignments or something like that. Mhm. So it sounds like you haven't really explored this shift shift shift left north stuff that hard. I mean, to me this sounds like the biggest problem to solve, really. Especially now with AI because you want AI agents to be in a little Why don't you just give them an AWS account? Cuz I'm not insane. No, I mean, why don't you just give a developer an AWS account so and a sandbox so that he can, you know, test it against the real AWS API services? Why would you try to emulate it? Like I don't get that. >> Because of speed. Speed and safety and >> you mock your tests, you get mock confidence. Yeah, I I I still maintain that this needs to be a bit explored a bit more further. I'll I'm going to bolden it. Oh my gosh. Okay, last topic. Cuz I need to run out and buy some bread. Orchestration uh can I assume that you that you and like most people nowadays just use GitHub workflows when you want to coordinate something or do you use something fancier to coordinate? I'm and you know, Is this the last topic? I don't know. I want to change the topic. >> [laughter] >> Can I change the topic? Sure. So you know, because I think there's more interesting with the trivy hacks and and basically the axios hack that happened and axios being on the registry with a infostealer for 2 3 hours before it was detected and removed. So I think right now and and actually it's funny because I just got a DM from someone that we both are trying to build something and I said I'm sorry, but I've been busy. I I've not been working on this because of other stuff, but if you want to work me to focus on this, I can like pick it back up. And he replied, "I've been really busy with these supply chain attacks." And I think it's it's actually a very interesting topic because everyone needs to change completely the way that we handle CVE and patch and you know, releases. So maybe I can give some background, right? The the established practice today to handle CVEs in the past was basically to adopt those fixes as soon as possible. So, if you use semantic versioning, you have three numbers. The first one is the major release, the second one is the minor release number, and the last one is the patch release number. Mhm. >> And so, usually if there's a CVE, which you're not introducing any new um features or you're doing a bug fix, you you bump that patch version number, the last number, right? If you're introducing new features, you do the minor, and if it's a massive breaking change, you do the the major uh release bump. So, the way that you use semantic versioning as a consumer of dependencies is by setting up some type of rules around or constraints around the packages that you accept, right? So, you can set up your your project, and this is something that people learned quickly when um they didn't put any constraints on the dependencies, and they just adopted minor and major um versions, and then they got hacked or they got uh impacted by those. So, people very quickly learned to put a constraint around dependency that you only accept uh patch releases or maybe sometimes minor releases, but usually just patch because minor release Well, not minor release shouldn't break you, right? Yeah, yeah, yeah, yeah, yeah. So, so the best practice right now that has been established long by Dependabot, Renovate, and others is to basically constantly check if any of your dependencies has a patch release. And then that usually indicates, because there's a CVE, you should upgrade as soon as possible. And so, Dependabot detects it, creates a pull request, and if you're really fancy, and I think a lot of people are, definitely if you manage many projects or open source projects, they set up an auto merge if all of the CICD pass, it immediately merges, right? So, that means that as soon as a patch release is published >> not quite fancy, but yeah, I mean No, all of the CDK, TN, all of the CDK, Terrain is auto bumping like that. >> I When I say fancy, I mean that's actually quite mature, but yeah, carry on. Yeah. Cool. So, you is the established best practice until today. Yeah. Because with the recent supply chain attacks, and a lot of those basically what happened is some projects get compromised, and the attackers are smart. They just push a patch release, right? So, everyone that's running Dependabot updates and pulls in this this package from the registry. So, this this best best practice works against people. And in the age of AI, there's been a lot more supply chain attacks, a lot more info stealers, a lot more like >> so there must be something to be said for people who don't update, right? I'm just looking at my notes. >> because if you don't update, you're still exposed to CVEs, which are also being detected first faster thanks to AI, because AI is analyzing codebases and finding CVEs faster. So, there are more patch releases. Yeah, it's between a rock and a hard place, isn't it? So, what you need to So, and so, I was asking around, how do I protect my project? Because we just forked, I don't want to get like a supply chain attack, and then all of the trust in the project dies. How do I make sure that this project is not on the newspaper? Maybe good and any news is better than than no news at all, right? I could just let it get hacked and then say, "Ah, people like Finally know there's a fork." No such thing as a bad publicity. Yeah, so anyway, I I don't intend to have it in the publicity in that way. So, I was asking around, and I really like how we're trying to solve this problem. It's an interesting thing to discuss as well. Cuz basically, a lot of these package managers, aside from you obviously fixing your long-lived credentials so that you they don't get stolen and using OIDC publishers so you get a short-lived credential to publish so that even if an info stealer got that key, it's already expired by the time it tries to use it. Yeah. Uh aside from first of trying to make sure that you don't get compromised that way, switch everything to OIDC for publishing. The other way is so that you don't get compromised as a consumer of these dependencies is to make sure that you use the feature that they have added, which is one, you can demand that the dependency must be older than X days or seconds. So, you can say to Dependabot or to the package manager, do not accept any package that hasn't been on the registry more than less than 3 days. Yeah, that sounds like a a very good approach, right? Because now if the package gets compromised, then hopefully it get discovered, and by the time you run, either it's been deleted or, you know, you shouldn't have it. Yeah, I guess that's like the Debian stable model, like it has to go through an unstable phase before it drops down into stability. And then the second thing is because I don't think that's enough, right? Maybe it was detected, but it wasn't taken down because of I don't know what reason, but usually NPM, G, actually the package registry managers will immediately take it down. Mhm. The second thing is you need to gate your CI, because your CI is not your unit test passing is not sufficient anymore for an auto merge. You have to run a security scan in your CI, right? And I was asking >> do that. A lot of people do that, but like >> Yeah, yeah. You were just saying it was fancy. Well, a a lot of people A lot of people do, but like I I I mean, I'm so worn down by Well, I'm not going to I'm going to say the name, Snyk. Like so many There's so many like noisy Snyk alerts Well, actually, because they have an open source supports option, I was thinking about, but I don't want to because we use it at work and I hate it. I don't even want to use it for my own source. >> What what what What are you talking about? Something What you just mentioned. >> Oh, okay, yeah. I don't I don't I don't mean to cast shade, but like it's probably like a user error, like we didn't configure it correctly or someone didn't configure it correctly. Some organ- inevitably org administrator applies it to every repo. So, every time you look at a repo, there's a bazillion security errors. You can hardly work through the mess. Okay. So, then then what I asked around and people told me is that actually NPM audit, in this case because we're doing the TypeScript projects, right? NPM audit is pretty good. So, Yeah, it is It is a great tool. So, when I talked about this auto update system that automatically merges the PR if everything's good, actually that's all built into Projen. Like you just have to enable a flag. You just say, "Yes, I want weekly updates. Yes, I want you to to make sure >> Okay. Yeah, and and Projen even switched from Yarn Classic because apparently Yarn Classic is not maintained and doesn't have any of those features. So, if you're on Yarn Classic, get off it, right? So, I'm moving everything from this inherited project from from CDK, TF, it's all using Yarn Classic. I'm migrating everything over to PNPM. Uh Projen migrated from Yarn Classic to NPM. They said it's good enough, it has everything we need, and it's less of a another hurdle for people to learn if they don't not familiar with it with with Yarn, Berry, or PNPM. But I'm using PNPM, I really like it. And Projen has support for PNPM dev dependency flag. So, you can just say like it must be older than 3 days, and I want you to run an NPM audit in the CI of that that job before it auto merges. It sounds like NPM in a way or no that that that ecosystem has the best tooling, because the the tooling in Python, I would say there isn't like an NPM audit. And that's what I was saying. Just that What do you want those guys to do for security? >> Yeah, that goes back to me bemoaning the data platform stuff. I mean, UV UV Astral would probably have those things, right? >> No, it doesn't really. Like the whole Astral update story is still a mess. Okay. That's not good. That's not good. So, yeah, I I think it was really cool because it's like um a really like really hot and and really interesting really. Uh because now you get like to play balance. But then, of course, the comment the first idea that most people have is like, "But if everything everyone is waiting to adopt a package, how are we even going to know if it's compromised?" Yeah, yeah, yeah. Cuz now everyone's going to wait 3 days before they they download it, and then they're only going to find >> imagine that that the NPM What whatever happens in NPM is going to be the the What is the the expression? It's like necessity is the mother of invention. The stuff that happens in NPM is on the forefront, right? And then it will trickle down to other ecosystems or the supply chain mitigations. So, so I have a lot of work to do in that aspect, actually. Like I still have to switch I have already enabled OIDC publishing on all the on all the registries, but I haven't switched over the actual publishers, the GitHub runners, to use OIDC. And Okay, you're like an NPM publisher deluxe, then I suppose. No, I'm like a NPM, NuGet, Maven, and PyPI publisher all across the board now. Yeah, that's That sounds kind of risky, actually. Yeah. I think I think I've got like I've got a couple of PyPI packages, and I've got a couple of NPM packages. I haven't uploaded to them for a while, but but yeah, I think they're both just passwords that I've never updated. Yeah. But then to to address the concern of people saying like, "But now everyone's waiting, so how are we going to know it's compromised?" But I think that that security companies have a real incentive, because every time And now they're like all over Reddit, like Step Security, but there's a couple of them, Roll Security. There's like a lot of security companies, and every time this happens, they're on Reddit posting, "There was this massive supply chain attack." They have an incentive to find to scan the packages published and find any info stealer, any type of you know, in injected whatever they they usually identify things like the package is unusually larger than than before. Yeah. The package has some base64 encoded like strings in there that are weird. So, they do this this uh heuristical scans to very quickly detect them. So, I don't think we need to worry about if everyone waits 3 days, it's not going to make detection slower. And then somebody said gave me an example, "What about exit utils?" I think exit util is is like a completely different scenario, right? What was the example? X XZ utils, which was a Yeah, yeah, yeah. I mean that that got that took months before it was detected and only because some Microsoft researchers saw his CPU spikes >> maybe it's worth maybe it's worth plotting this in a in Excalidraw. Let me just public searchable cuz I do you think it's worth capturing? Which one? Like Z utils or what we just discussed? What we just discussed like um I'm just sharing my screen. And now we I just want to capture it. I just wanted to capture some roughness. So I thought it was really cool, interesting. Aside from obviously the Claude Code source code map leak, which has been talked about for death. Um I think the the scenario the whole situation around Trevi being a complete Is it it's Aqua Security that's that was completely compromised, no? Okay, so doing forgot how to use this thing. So the Uh we started by saying that like developers with uh you know, a password can can get compromised. Since they aren't using OIDC. So that that could happen. So that's that's one angle of of attack. I'm just I'm just wanted since they aren't using short-lived credentials. Yeah, yeah. It's not necessarily just OIDC, right? Oh my god. Aqua Security posted an update yesterday as well on on Wednesday, 2 days ago. The other angle is that people are not using uh security scanners. Yeah, but if you use Aqua Security scanner you got compromised. If you were using Trevi, you got compromised. Trevi is the exception. I I just wanted to plot like the the typical ways that supply chain I mean, there's probably a better list somewhere already. Um at least the ones that we talked about. Um and then there was a third one. What Sorry, I I lost I was too busy typing. What's What is the third one? Well, well, I guess what what you just said like the NPM will will will take that will will will catch it. Uh given you know, X Y X days of cool down or something like that. You know, like like the like the XC or something. >> It's something called um age. The package The age of the package has to be above. Let me find I did a pull request on the CDK terrain repo um provider project's old one. All these security companies have Has Has anyone Have these security companies actually said that we have stopped attacks on NPM? I want I I mean, does NPM use a security scanner? Yeah, I don't think they do because I think when when Microsoft owns NPM Microsoft owns NPM. Oh, really? Yeah. Let me check. >> even know that. NPMGS I mean, like the official registry owned by GitHub. So yes, Microsoft. You understand what I'm saying? Like when I maybe I have a bad memory, but when I published NPM, it's like pretty much instant. So that means there's no there's no gate, right? It It They They just publish it immediately. I think so, yeah. So it makes makes me think is this step two people are not using security scanners? Include does does NPM do this? Something to look into. Anyway, it's a it is an interesting space. It's a space So if you use PNPM, the flag is config.minimum release age and you have to provide the number in minutes. So I've just set it up as 4 days. Which is 5,760 minutes. >> parameter called? Minimum Minimum like config yeah, minimum-release-age. Oh, cool. Not underscore, but dash, but okay, don't matter. And then the second thing is you can run NPM audit with audit levels. Yeah, NPM audit is really good. NPM audit. And the guy like who maintains Projen told me he finds it good enough. And And honestly, he's also the guy I was talking to about doing some something else and he says that he hasn't been able to work on it because and he's on AWS. He says because of these supply chain attacks have been taking all of his time. Projen is heavily used within AWS as far as I understand. The way that they maintain all of their repository boilerplate is with Projen. So all of these features allow AWS to very quickly roll out like these settings across all of their repositories, right? You just update the core project and then every repo adopts it and and and reconfigures itself accordingly. Which is a dream, by the way. Like um even here with this CDK terrain provider like with the CDK terrain setup that I inherited from HashiCorp, it's all managed by Projen and Terraform for GitHub. So >> The tooling that The tooling is really good when I think about it. >> It is really nice. Because I tried to roll out Projen within my organization as well, but again it's niche, it's complicated. >> is a is is CDK ecosystem very very very I mean, but Have we ever talked about Projen? Projen's TypeScript or It's written in TypeScript. Oh, it's available for Go? What? >> Yeah, because it uses JSII, right? Oh. How is it You wouldn't You wouldn't want to put it in a Go language project. How can you say if you never tried? Yeah, I I I guess I should >> It supports Python and they also support you UV in it now. Like the good thing about Projen is that it's that actually quite a lot of people use it even though not a lot of people know about it and that means that it's been kept up to date with like quite recent frameworks. We haven't updated the CDK TF supporting there yet. We have to switch Projen all the way over to CDK terrain. Um but it it really gives you like really good um Okay, so you know how GitHub has this amazing feature of creating a template repository, right? >> Yeah. Absolutely hate it. What happens after you create it? >> say it's sarcastic uh [snorts] amazing. Okay, carry on. >> So So And And not just updated. Yeah, and then and then people have to come up with all kinds of workarounds to >> Like at at my last workplace, there was uh actually the the workaround that we have was pretty good. It was like a pack pack new inspired. I don't know if you know Arch Linux. But basically, we wrote files into people's repositories with the suffix dot new. Okay. So So but still, you need a whole bunch of additional stuff, right? Um because the biggest problem of these scaffolding framework um libraries and cookie cutter and all this is that they will bootstrap a file system for you once and then that's it, right? How do you keep that updated? Most of them don't take that into account. So Projen is different in a way that it approaches the file system exactly the same way as it deals with like a construct tree in uh AWS CDK. So every file is basically an object in memory that you construct up into a tree. And then finally, when you have defined what the contents of the file is to look you know, on that particular path, when you when you synthesize, it writes everything down to disk, okay? So then it creates the whole I'm I'm understanding like it keeps your answers. It keeps your values. Yeah, and it it you can even have a function to lazily determine the contents of a file at the very end during synthesis, right? By you know, collecting all of the other files that have been generated and then generating the contents of that file. So you're able to completely functionally define the contents of your of your file system. And and and what's good about it is that you can also hook into the process. Like with with CDK and AWS CDK and CDK Terraform, you can before synthesis do some activities go on fun activities. No, but like what you can do is you can programmatically control the contents of the file, which also means that the consumer can define patches on top of the files. So he can go find a certain file within the tree and then add additional lines or do additional things because he in his case So that means that if the if the root project or the root object that built your construct your tree of objects has changes they will all just be adopted and regenerated your file system on disk and then your patches get rerun on top of it and get reapplied as well. As long as those two don't conflict, you know, it will just re-render the file system with your patches applied. So you can constantly keep updating the the source and then roll it out and it's all programmatic. So >> Yeah. So that's I mean, this is this is applicable for for a platform where you're supporting lots of products, I guess, right? I mean, that's the big reason. Yeah, so so where Projen really shines is in like a poly repo setup because it has really good support for like a single repo with just one package in it that needs to be published. If you start to deal with one repository and you need to support publishing multiple packages then it becomes a little bit more complicated. They have built support for that on top of Projen. But to be honest, I I never managed to make it work because this is the main reason I was not able to roll it out at work is because we we have a lot of repositories that are publishing multiple packages and so I had adopted Turbo repo. And you know, it's easy to build your own project type in Projen because you can define your object, which is a project type, and you can determine what are what is it like and and it works with add-ons. So yeah, you can create one object, which is like I'm going to take care of the GitHub workflows and I'm I'm an object that's going to take care of the I don't know, your your package.json, your your YAML, like your your your manifest for your package. So So it support all of these in like add-ons. So you can say now I have a repo, a base project, and I'm going to add on the GitHub actions object and it's going to generate my actions. That sounds really powerful. I mean, it sounds really handy for publishers like yourself who you know, CDK terrain. I mean, you you must be maintaining quite a few projects, right? >> just one. Yeah, yeah, we are maintaining a lot of projects, but we just have one project type in Projen that manages all of our providers. Yeah, yeah, yeah, yeah, yeah. So, so we just define a provider within the project is Yeah. this. And it comes with like it go it comes with jobs to go and check the Terraform registry if there's a new version of the provider, and then it will if there's a a new version, it will regenerate the bindings. I know my internet just hiccuped, right? But um >> It didn't my word. Yeah, but it will be fine on the recording. Yeah, yeah, I got to edit this. Cool, man. I I I got to rush out and buy some bread before this the baker sells out and enjoy a few days offline, I think. That's my mission. Not spend spend some more time with my kids since they're not they're on holiday now. Yeah. So, I'll I get back to you next week. And next week did I I I mentioned to you I'm going to this AI engineer conference today? Yes, you mentioned it. >> I'll I'll have some I'll have a lot more to say next week. Or the week after. I'll send you a link. We'll catch up then. Okay, see you. All the best. Have a good Easter. Yeps. Uh yeah, happy Easter. Yeah, are you going to do anything? No? No. You don't have Easter in Vietnam. You have other things. Yeah, but I'm on this very annoying contract where I don't have any ability to take leave, so I'm not taking any. >> of all time. Exactly. See you, man. Bye. Okay, bye.