Episode 33: BAU is fun with AI
Published: Thursday, May 21, 2026 • Duration: 52 minutes • Season 1

Download MP3 | Watch on YouTube
Chapters
00:00 Coffee and Casual Conversations 02:53 Automation in Cloud Infrastructure 06:07 Navigating Complex Repositories 08:58 The Role of Jira in Development 11:58 Ad Hoc Workflows and Planning 15:01 Using Work Trees for Parallel Development 17:55 Attribution and AI in Development 21:02 Managing PRs and Workflows 24:06 Productivity with Cloud Code and AWS Vault 27:17 Exploring AWS CLI and Vault Integration 30:51 AI in Workflow Automation 32:49 The Cost of AI and Token Management 36:01 Enhancements in Cloud Tools and Features 39:48 Spec-Driven Development and Code Review Dynamics 51:25 Reflections on Spec-Driven Development Challenges
summarize "https://youtu.be/6RsV8yQuB6I" --timestamps --slides
A run‑through of a casual conversation about daily ops work (BAU) made easier with AI agents: the hosts cover how they use Cloud Code and an LLM assistant (Claude) to automate infrastructure changes, explore complex repos, manage Jira-linked workflows, parallelize edits with Git worktrees, and handle AWS credentials and troubleshooting.
Morning chat and setup
The video opens with informal banter (coffee, oversleeping, family logistics) and quickly shifts to work context: the speaker has limited time but plenty of actionable tasks, and frames recent days as “insane” but satisfying because they produced tangible results. The tone is conversational and sets up the rest of the session as a practical tour of real BAU tooling rather than a theoretical demo.
Cloud Code as an agent for infra automation
Cloud Code in auto mode acts like an agent that wakes on events and runs a classic Terraform pull‑request automation flow. The speaker describes a setup where CDK‑TF TypeScript defines infrastructure inside the product repo (a TurboRepo workspace package), the infra package synthesizes Terraform, and Atlantis performs auto plans and applies against a dev workspace. The flow: change infra package → PR shows Terraform plan against dev → dev apply runs and results in a versioned change set → release PR publishes the infra package to a private registry → integration repo picks up the package and promotes releases through integration → staging → prod. Cloud Code monitors related repos, triggers Atlantis apply after PR approval, and links infra and container artifacts so infra and Dockerfile changes propagate immutably through environments. The speaker calls this combination “agents plus a fully automated CICD pipeline, uh, is amazing.” (excerpt)
Using Claude to analyze and “shift left” on repo workflows
When a repo lacks documentation, the speaker uses Claude to reverse‑engineer workflow from Git history: branches, merges, PR timing and release branch lifecycle (release branches created off master, deleted after production). Claude inspects branches and PRs to recommend target branches for new PRs and helps produce a release‑flow markdown for human review. For multi‑team or legacy repos with many environment branches, Claude gathers context before planning — the recommended pattern is to “go through exploration phases, read some Jira tickets, read some GitHub issues” (excerpt) and optionally have the agent look at Git history to suggest where to apply changes. The speaker emphasizes not revealing which LLM in PRs for internal reasons.
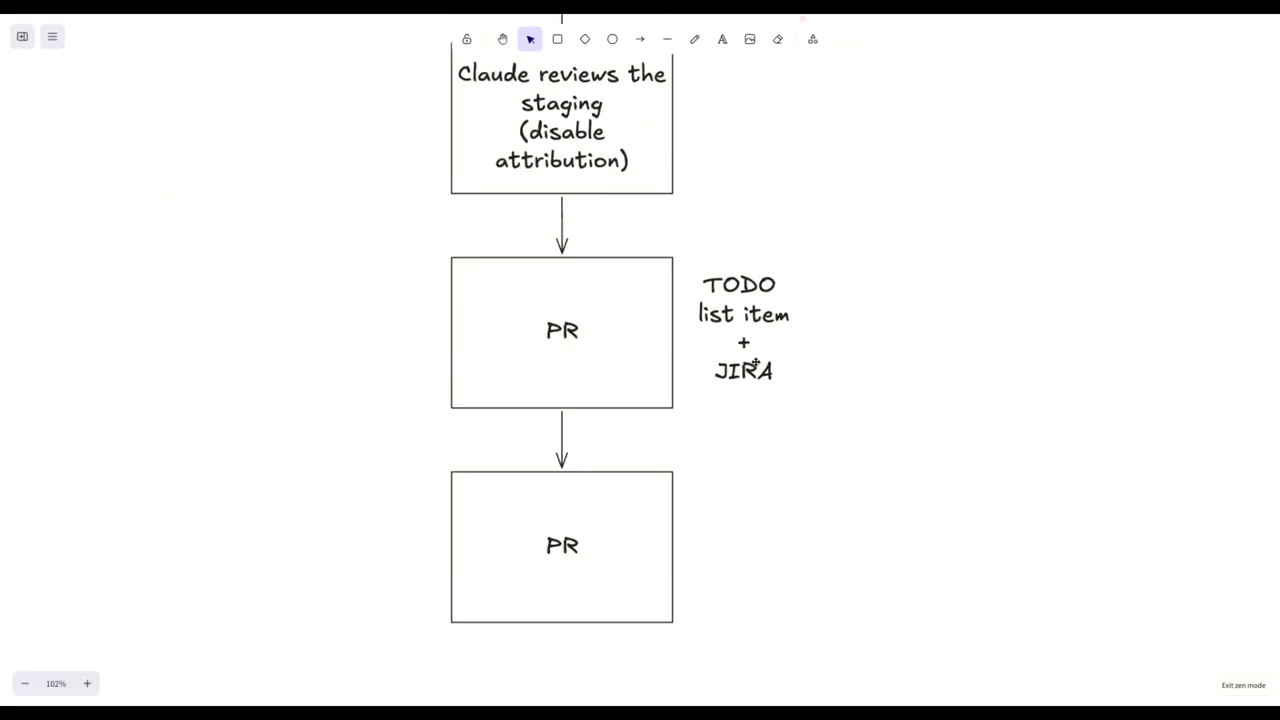
Jira, task tracking, and spec‑driven tradeoffs
The conversation reassesses Jira: earlier hostility to Jira is softened—Jira is described as useful for coordinating team status across environment promotions. The speaker uses a custom Jira CLI/skill that maps board statuses to their workflow and links subtasks to track multi‑PR work (e.g., one Jira ticket coordinating three or four PRs). For startups or tightly spec‑driven repos, the speaker suggests you might avoid Jira and keep everything in Git with a lightweight Kanban overlay, but in enterprise contexts Jira remains practical. They also note spec‑driven content dumped into Jira is the wrong use; Jira is for human coordination.

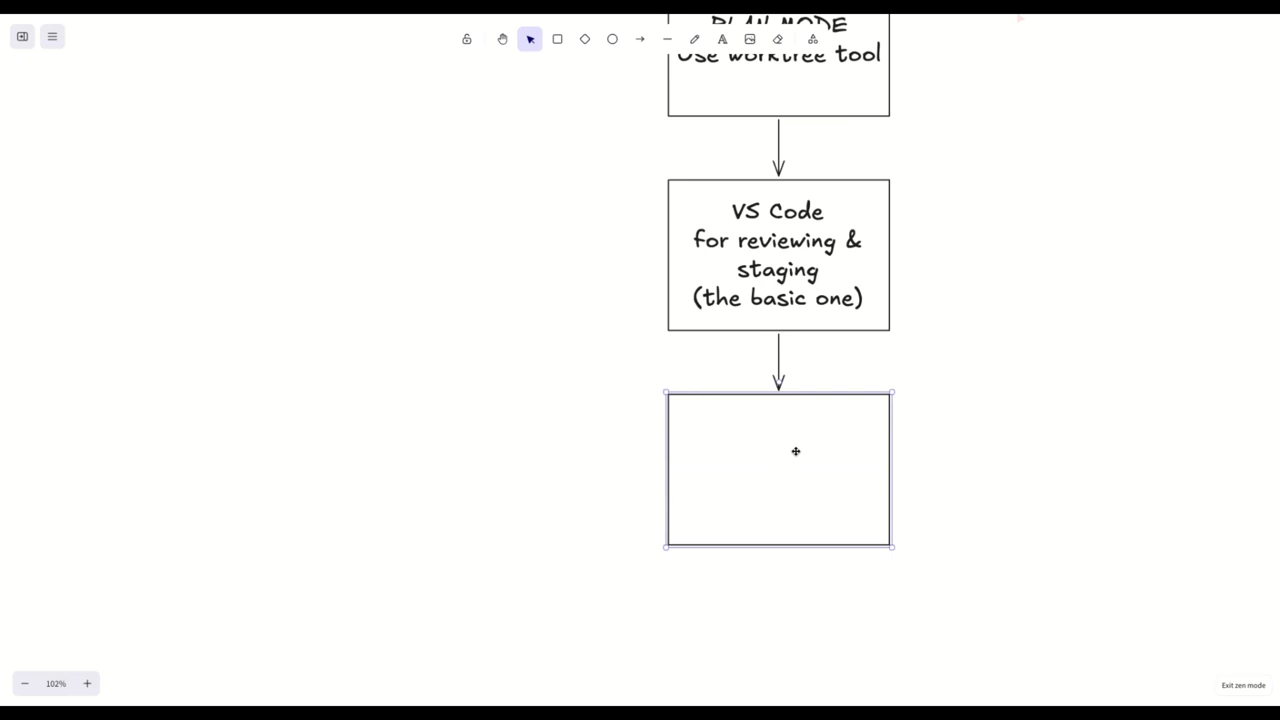
Worktrees, plan mode, and agent ergonomics
A key operational pattern: avoid entering plan mode immediately in brownfield/ad hoc work; instead run exploration agents first. The workflow described: launch an asynchronous explorer to summarize the repo and relevant issues, then switch into plan mode once scope is clear. Use the Cloud Code work tree tool (it creates Git worktree directories under .cloud) so each agent session is isolated in its own checked‑out directory and cleaned up automatically when finished. Benefits: run parallel agents/terminals, stage files in VS Code to inspect diffs before committing, and let agents create PRs per worktree. The speaker stages files manually between agent iterations to verify changes and relies on Cloud Code to detect unstaged files during its local verification. They contrast branches vs worktrees: worktrees are separate directories checked out to branches, enabling parallel sessions without full clones.
To‑do tooling, AWS Vault, and troubleshooting remote nodes
Cloud Code’s to‑do list tool (session‑ or cross‑session scoped) lets agents persist and drive multiple sub‑tasks without pausing for human prompts; when asked to use to‑do lists, Claude tracks tasks and continues until completion, creating multiple sequential PRs or parallel work where needed. For cloud access the speaker uses AWS Vault (CLI-based, uses OS keychain/pass) to obtain short‑lived credentials and SSO sessions; Claude knows AWS Vault and can list available sessions, launch one, and run commands. The keychain prompts for approval (password/fingerprint) when using credentials. For remote debugging the speaker notes using SSM inventory and run‑commands from an agent to perform network troubleshooting on an EC2 node, and contrasts that with other approaches (cloud shell with an LLM inside it). They close by describing this agent+worktree+Vault pattern as turning tedious multi‑PR ops into a productive parallel workflow that makes BAU feel manageable.
Model: openai/gpt-5-mini